[境界要素法プログラムを設計する([計算部]の完成)] [境界要素法]
[境界要素法プログラムを設計する([計算部]の完成)]
1.Free Termの処理
もう一度[内点方程式から境界方程式へ(ラプラス型)]のFree Termの項を考えます。

図-1でε→0の極限を取った場合、式(1)のψ(ξ,η)の(ξ,η)は、節点j+1に一致します。つまりψ(ξ,η)→ψj+1です。よって、

となります。式(2)の最後の形のψj+1の係数の2項目が、境界積分関数で与えられるGam_12です。

節点jが角点の場合、
![]()
になるのでした。kj+1は節点j+1の内角です。ところで今は、角点のない解析領域に対応するプログラムを作成中です。節点が角点でない場合、[境界方程式に関する留意点(ラプラス型)]によればkj+1/2/π→1/2におきかえるのが一般的でした。滑らかな境界点の場合、kj+1=πと考えられるからです(β(j+1)=β(j)だから)。
よってメインの「REM 境界要素番号kで境界積分を行うLoop」で全体係数マトリックスA、
![]()
を作った後、式(5)のBブロックの対角成分を1/2に上書きする必要があります。上記のLoopの後に、次のコードを追加します。
(「境界要素番号kで境界積分を行うLoop」の後)
REM Bマトリックスの滑らかな境界節点のFree Termを1/2に上書きするLoop
For i = 1 to BN_Count
A(i, i) = 1 / 2
Next i
2.Declare文を追加する
前回の結果より、境界積分のために外部関数Length,Angle,Normal_Param,Normal_Length,Normal_Foot,B_Inte_B1,B_Inte_B2,B_Inte_H1,B_Inte_H2を使用するのでした。これらのDeclare文を追加します。
追加する場所はどこか?という問題があります。個人的な趣味では、これらを使うのは「境界要素番号kで境界積分を行うLoop」なので、道具は「実行者」のすぐそばに置いておきたいのですが、個人的趣味ばかり押し出すと嫌われそうなので(^^;)、普通に[計算部]冒頭に置く事にします。
3.Gauss掃き出し法のサブルーティン名を決める
Gauss掃き出し法のサブルーティン名と引数は、Gauss_0(A, z, n, Zero_Order, Return_Code)としておきます。この名前は趣味です!(←舌の根も乾かぬ内に・・・(^^;))。Gauss_0のDeclare文も[計算部]冒頭に追加します。
A,zの意味はいいと思うので省略します。nは未知数の数(=2*BN_Count),Zero_Orderは正の整数でピボットの0判定条件に使います。つまりピボットの絶対値がEps=10^(- Zero_Order)未満だったら、特異行列です。自分はたいてい、Zero_Order=8を使います。
ピボットの意味がわからなかったら、ネコ先生の記事を読もう!(^^)。
Return_Codeは計算終了時の状態を表し、Return_Code = 0~2の値を取るものとします。Return_Code=0は「正常終了」(ちゃんと連立方程式が解けた)、Return_Code=1は「0の行がある」、Return_Code=2は「特異行列である」だとしておきます。これらはユーザーには関係ないです(プログラマーでないユーザーには(^^))。
だって正常終了しなかったら、開発中のプログラムは間違てるって事ですから。しかし「プログラマー」という、「ユーザーにとっては」まずデバック時に非常に役立ちます(^^)。だからReturn_Codeの値によってはメッセージを出し、無駄な出力も行わないで強制終了するような制御も入れておきましょう。
リリースしたらその制御は発動しない事を願うのみですが、間違って発動したら「旦那、どんなメッセージが出やした?」ってお客さんに犬のようにきけるんですよ(^^)。それは間違い修正やメンテナンスに対する、非常に得難い情報になります。そしてFortranではそのような行為を「旗を立てる」と言いました(^^)。
以上まとめると以下です。
REM [計算部]
External Function Length
External Function Angle
External Function Normal_Param
External Function Normal_Length
External Function Normal_Foot
External Function B_Inte_B1
External Function B_Inte_B2
External Function B_Inte_H1
External Function B_Inte_H2
External Sub Gauss_0
REM 境界要素番号kで境界積分を行うLoop
For i = 1 to BN_Count
REM 特異点番号iの節点iを特定
x0 = BN(i, 1) REM 節点iの(x,y)座標
y0 = BN(i, 2)
For k = 1 to B_Count
REM 要素番号kからEN_B(k,2)に従い節点を特定し、要素ごとに境界積分を実行
j1 = EN_B(k,1) REM 要素kの始端の節点番号
j2 = EN_B(k,2) REM 要素kの終端の節点番号
x1 = BN(j1, 1) REM 節点j1の(x,y)座標
y1 = BN(j1, 2)
x2 = BN(j2, 1) REM 節点j2の(x,y)座標
y2 = BN(j2, 2)
REM (x0,y0),(x1,y1),(x2,y2)から、要素kの境界積分値を計算
REM 積分パラメータ計算
Lk = Length(x1,y1,x2,y2)
r1 = Length(x0,y0,x1,y1)
r2 = Length(x0,y0,x2,y2)
Gam_12 = Angle(x0, y0, x1,y1,x2,y2, r1, r2, Eps)
t = Normal_Param(x0, y0, x1,y1,x2,y2)
h = Normal_Length(x1,y1,x2,y2, t)
s = Normal_Foot(x0, y0, x1,y1,x2,y2, t)
REM ψj1に関する結果をB1,qj1に関する結果をH1で表す
REM ψj2に関する結果をB2,qj2に関する結果をH2で表す
B1 = B_Inte_B1(Lk, r1, r2, Gam_12, h, s, Eps)
B2 = B_Inte_B2(Lk, r1, r2, Gam_12, h, s, Eps)
H1 = B_Inte_H1(Lk, r1, r2, Gam_12, h, s, Eps)
H2 = B_Inte_H2(Lk, r1, r2, Gam_12, h, s, Eps)
REM 上記結果に基づき、係数マトリックスBとHを作成
jj1 = BN_Z(j1,1) REM ψj1の解ベクトルzの中での位置
jjj1 = BN_Z(j1,2) REM qj1の解ベクトルzの中での位置
jj2 = BN_Z(j2,1) REM ψj2の解ベクトルzの中での位置
jjj2 = BN_Z(j2,2) REM qj2の解ベクトルzの中での位置
A(i, jj1) = A(i, jj1) - B1
A(i, jjj1) = A(i, jjj1) + H1
A(i, jj2) = A(i, jj2) - B2
A(i, jjj2) = A(i, jjj2) + H2
Next k
Next i
REM Bマトリックスの滑らかな境界節点のFree Termを1/2に上書きするLoop
For i = 1 to BN_Count
A(i, i) = 1 / 2
Next i
REM 領域要素番号kで領域積分を行うLoop
For i = 1 to BN_Count
REM 特異点番号iの節点iを特定
h = 0
For k = 1 to R_Count
REM 要素番号kからEN_R(k,4)に従い節点を特定し、要素ごとに領域積分を実行
REM 特異点iと要素節点情報から積分値w0を計算
h = h + w0
Next k
REM 上記結果に基づき、既知ベクトルwを作成
z(i) = h
Next i
REM 境界節点番号jで境界条件位置を指定するLoop
For i = BN_Count + 1 to 2 * BN_Count
REM 行番号から節点番号を特定する
j = i - BN_Count
REM 節点番号jからBN_BP(j,2)とBN_Z(j,2) に従い、(D1 D2)ブロックを作成
REM 節点番号jに従いBN_BV(j,2)の値をwブロックの後に並べ、(d1 d2)ブロックを作成
If BN_BP(j,1) = 1 Then
REM ψjが既知が場合
jj = BN_Z(j,1) REM ψjの解ベクトルzの中での位置
A(i, jj) = 1 REM ψjの値を与えるので、Aの成分は1
z(i) = BN_BV(jj,1) REM ψjの値
ElseIf BN_BP(j,2) = 1 Then
REM qjが既知が場合
jj = BN_Z(j,2) REM qjの解ベクトルzの中での位置
A(i, jj) = 1 REM qjの値を与えるので、Aの成分は1
z(i) = BN_BV(jj,2) REM qjの値
End If
Next i
REM 全体係数行列が出来たので、Gaussの掃き出し法にかけ、未知ベクトルzを求める
Zero_Order = 8
Call Gauss_0(A, z, 2 * BN_Count, Zero_Order, Return_Code)
If Return_Code = 0 Then
Print "正常終了しました。"
ElseIf Return_Code = 1 Then
Print "0の行があります。"
End
ElseIf Return_Code = 2 Then
Print "特異行列です。"
End
End If
REM [外部手続き]
REM 境界積分パラメータ ****************************************
External Function Length(x1,y1,x2,y2)
Length = Sqr((x2 - x1)^2 + (y2 - y1)^2)
End Function
External Function Angle(x0, y0, x1,y1,x2,y2, r1, r2, Eps)
If r1 < Eps Then
x01 = 1
y01 = 0
x02 = x2 - x1
y02 = y2 - y1
r1 = 1
ElseIf r2 < Eps Then
x01 = x1 - x2
y01 = y1 - y2
x02 = 1
y02 = 0
r2 = 1
Else
x01 = x1 - x0
y01 = y1 - y0
x02 = x2 - x0
y02 = y2 - y0
End If
Gum_12 = Acos((x01 * x02 + y01 * y02) / r1 / r2)
Sign = Sgn(x01 * y02 - x02 * y01)
Gum_12 = Gum_12 * Sign
Angle = Gum_12
End Function
External Function Normal_Param(x0, y0, x1,y1,x2,y2)
a = x2 - x1
b = y2 - y1
t = (b * (x1 - x0) - a * (y1 - y0)) / (a^2 + b^2)
Normal_Param = t
End Function
External Function Normal_Length(x1,y1,x2,y2, t)
a = x2 - x1
b = y2 - y1
h = Abs(t) * Sqr(a^2 + b^2)
Normal_Length = h
End Function
External Function Normal_Foot(x0, y0, x1,y1,x2,y2, t)
a = x2 - x1
b = y2 - y1
s = Sqr((t * b + x0 - x1)^2 + (-t * a + y0 - y1)^2)
Normal_Foot = s
End Function
REM 境界積分 **********************************************
External Function B_Inte_B1(Lk, r1, r2, Gam_12, h, s, Eps)
If r1 < Eps Then
B1 = Gam_12 / 2 /Pai
ElseIf r2 < Eps Then
B1 = 0
Else
B1 = Gum_12 - 1 / Lk * (s * Gum_12 + h * (Log(r2) - Log(r1)))
B1 = B1 / 2 /Pai
End If
B_Inte_B1 = B1
End Function
External Function B_Inte_B2(Lk, r1, r2, Gam_12, h, s, Eps)
If r1 < Eps Then
B2 = 0
ElseIf r2 < Eps Then
B2 = Gam_12 / 2 /Pai
Else
B2 = 1 / Lk * (s * Gum_12 + h * (Log(r2) - Log(r1)))
B2 = B1 / 2 /Pai
End If
B_Inte_B2 = B2
End Function
External Function B_Inte_H1(Lk, r1, r2, Gam_12, h, s, Eps)
If r1 < Eps Then
H1 = Lk / 4 / Pai * (Log(Lk) - 3 / 2)
ElseIf r2 < Eps Then
H1 = Lk / 4 / Pai * (Log(Lk) - 1 / 2)
Else
H1 = -1 / 4 / Pai / Lk * (r2^2 * Log(r2) - r1^2 * Log(r1) - 1 / 2 *((Lk - s)^2 - s^2))
H1 = H1 + 1 / 2 / Pai * (1 - s / Lk) * (h * Gum_12 + (Lk - s) * Log(r2) + s * Log(r1) - Lk)
End If
B_Inte_H1 = H1
End Function
External Function B_Inte_H2(Lk, r1, r2, Gam_12, h, s, Eps)
If r1 < Eps Then
H2 = Lk / 4 / Pai * (Log(Lk) - 1 / 2)
ElseIf r2 < Eps Then
H2 = Lk / 4 / Pai * (Log(Lk) - 3 / 2)
Else
H2 = 1 / 4 / Pai / Lk * (r2^2 * Log(r2) - r1^2 * Log(r1) - 1 / 2 *((Lk - s)^2 - s^2))
H2 = H2 + 1 / 2 / Pai * s / Lk * (h * Gum_12 + (Lk - s) * Log(r2) + s * Log(r1) - Lk)
End If
B_Inte_H2 = H2
End Function
REM Gauss掃き出し法 **********************************************
External Sub Gauss_0(A, z, Zero_Order, Return_Code)
REM まだ何にもしない
End Sub
[境界要素法プログラムを設計する(境界積分サブルーティン:実装編)] [境界要素法]
[境界要素法プログラムを設計する(境界積分サブルーティン:実装編)]
1.積分パラメータ関数の実装
前々回、メインの中に与えた境界積分サブルーティン(関数)は、以下でした。
REM (x0,y0),(x1,y1),(x2,y2)から、要素kの境界積分値を計算
REM ψj1に関する結果をB1,qj1に関する結果をH1で表す
REM ψj2に関する結果をB2,qj2に関する結果をH2で表す
Lk = Length(x1,y1,x2,y2)
Beta_k = Angle(x2 - x1, y2 - y1, Lk)
r1 = Length(x0,y0,x1,y1)
r2 = Length(x0,y0,x2,y2)
Gamm_1 = Angle(x1 - x0, y1 - y0, r1)
Gamm_2 = Angle(x2 - x0, y2 - y0, r2)
h = Normal_Length(x2 - x1, y2 - y1, x0,y0)
s = Normal_Foot(x2 - x1, y2 - y1, x0,y0, h)
B1 = B_Inte_B1(Lk, r1, r2, Beta_k, Gamm_1, Gamm_2, h, s)
B2 = B_Inte_B2(Lk, r1, r2, Beta_k, Gamm_1, Gamm_2, h, s)
H1 = B_Inte_H1(Lk, r1, r2, Beta_k, Gamm_1, Gamm_2, h, s)
H2 = B_Inte_H2(Lk, r1, r2, Beta_k, Gamm_1, Gamm_2, h, s)
最初にLength関数ですが、明らかに次でOKです。
External Function Length(x1,y1,x2,y2)
Length = Sqr((x2 - x1)^2 + (y2 - y1)^2)
End Function
前々回に予告したように、関数とサブルーティンはローカル変数を持てる、外部手続きで統一します。Normal_LengthとNormal_Footの計算に疑問の余地はないのですが、ちょっと長そうなので後にします。
次にBeta_kの扱いですが、前回の検討からGamm_1,Gamm_2の特殊ケースとして扱って良いとわかりました。という訳でGamm_1とGamm_2の計算です。これらは単独に計算しては駄目で、Gamm_2-Gamm_1の形で計算する必要がありました。それをGam_12で表します。
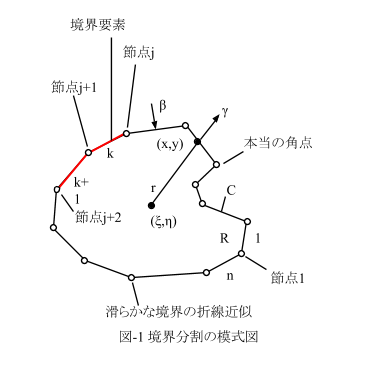
まず特異点(x0,y0)が要素節点(x1,y1)と(x2,y2)に一致しないケースから考え始めると、わかりやすいと思います。以下、前回を参照しつつ・・・。
計算開始の前提として、図-1のr1,r2および(x0,y0),(x1,y1)と(x2,y2)は引数渡しされるとします。また特異点と要素節点の一致/不一致判定のために、0距離判定値Epsも必要です。
External Function Angle(x0, y0, x1,y1,x2,y2, r1, r2, Eps)
If r1 < Eps Then
x01 = 1
y01 = 0
x02 = x2 - x1
y02 = y2 - y1
r1 = 1
ElseIf r2 < Eps Then
x01 = x1 - x2
y01 = y1 - y2
x02 = 1
y02 = 0
r2 = 1
Else
x01 = x1 - x0
y01 = y1 - y0
x02 = x2 - x0
y02 = y2 - y0
End If
Gum_12 = Acos((x01 * x02 + y01 * y02) / r1 / r2)
Sign = Sgn(x01 * y02 - x02 * y01)
Gum_12 = Gum_12 * Sign
Angle = Gum_12
End Function
r1 < Eps(r1=0)の時は、(x01,y01)=(1,0)とするのでした。この時(x0,y0)は(x1,y1)に一致するとみなせるので、(x02,y02)=(x2 - x1,y2 - y1)です。そしてr1=1とします。
r2 < Eps(r2=0)の時は、(x02,y02)=(1,0)とするのでした。この時(x0,y0)は(x2,y2)に一致するとみなせるので、(x01,y01)=(x1 - x2,y1 - y2)です。そしてr2=1とします。
以上より、積分パラメータを与える関数呼び出しは、
Lk = Length(x1,y1,x2,y2)
r1 = Length(x0,y0,x1,y1)
r2 = Length(x0,y0,x2,y2)
Gam_12 = Angle(x0, y0, x1,y1,x2,y2, r1, r2, Eps)
h = Normal_Length(x0, y0, x1,y1,x2,y2)
s = Normal_Foot(x0, y0, x1,y1,x2,y2)
になります(Normal_Length,Normal_Footの引数が前回のままでは不味いと気付いた(^^;))。
Normal_Lengthの実装は以下です。Normal_Lengthは図-1の垂線距離hを求めます。
a = x2 - x1
b = y2 - y1
とすると、(x1,y1)と(x2,y2)を通る直線は、y=b/a*xに平行です。a=0の場合も考慮して、これをbx-ay=0の形にし、(x1,y1)を通る事を考慮すると要素kの直線の方程式は、b(x-x1)-a(y-y1)=0になります(なんか受験を思い出すなぁ~(^^))。直線の式からその垂線ベクトルの方位は、明らかに(b,-a)です。従って点(x0,y0)からの垂線は、tを任意の実数として、
![]()
と書けます。(1)がb(x-x1)-a(y-y1)=0に載る条件は、(1)を代入し、
![]()
(2)をtについて解くと、

従ってhは、tが(3)の値の時、
![]()
tを利用すれば垂線の足もわかるので、図-1のsも出せます。垂線の足の座標は、tを(3)の値にした(1)です。よってsは、
![]()
から、
![]()
です。
こうなるとNormal_LengthとNormal_Footで同じパラメータtを利用したいですよね。こうしましょう。
h = Normal_Length(x1,y1,x2,y2, t)
s = Normal_Foot(x0, y0, x1,y1,x2,y2, t)
External Function Normal_Param(x0, y0, x1,y1,x2,y2)
a = x2 - x1
b = y2 - y1
t = (b * (x1 - x0) - a * (y1 - y0)) / (a^2 + b^2)
Normal_Param = t
End Function
External Function Normal_Length(x1,y1,x2,y2, t)
a = x2 - x1
b = y2 - y1
h = Abs(t) * Sqr(a^2 + b^2)
Normal_Length = h
End Function
External Function Normal_Foot(x0, y0, x1,y1,x2,y2, t)
a = x2 - x1
b = y2 - y1
s = Sqr((t * b + x0 - x1)^2 + (-t * a + y0 - y1)^2)
Normal_Foot = s
End Function
2.境界積分関数の実装
以上で境界積分に必要な積分パラメータは全て揃いました。
B1 = B_Inte_B1(Lk, r1, r2, Gam_12, h, s, Eps)
B2 = B_Inte_B2(Lk, r1, r2, Gam_12, h, s, Eps)
H1 = B_Inte_H1(Lk, r1, r2, Gam_12, h, s, Eps)
H2 = B_Inte_H2(Lk, r1, r2, Gam_12, h, s, Eps)
で良いはずです。引数の最後にEpsが入るのは、これらでも特異点と要素節点の一致/不一致判定が必要だからです。
後はB_Inte_?の中に、[内点方程式の積分公式(ラプラス型)]と[内点方程式から境界方程式へ(ラプラス型)]で導出した式を並べるだけですが、関数の内部構造はExternal Function Angleと同一構造になるとわかります。なのでIfブロックの形を決め、「関数名 = 値」の行を書いてから、計算式を並べる事をお奨めします。
If r1 < Eps Then
B1 = Gam_12 / 2 /Pai
ElseIf r2 < Eps Then
B1 = 0
Else
B1 = Gum_12 - 1 / Lk * (s * Gum_12 + h * (Log(r2) - Log(r1)))
B1 = B1 / 2 /Pai
End If
B_Inte_B1 = B1
End Function
External Function B_Inte_B2(Lk, r1, r2, Gam_12, h, s, Eps)
If r1 < Eps Then
B2 = 0
ElseIf r2 < Eps Then
B2 = Gam_12 / 2 /Pai
Else
B2 = 1 / Lk * (s * Gum_12 + h * (Log(r2) - Log(r1)))
B2 = B1 / 2 /Pai
End If
B_Inte_B2 = B2
End Function
External Function B_Inte_H1(Lk, r1, r2, Gam_12, h, s, Eps)
If r1 < Eps Then
H1 = Lk / 4 / Pai * (Log(Lk) - 3 / 2)
ElseIf r2 < Eps Then
H1 = Lk / 4 / Pai * (Log(Lk) - 1 / 2)
Else
H1 = -1 / 4 / Pai / Lk * (r2^2 * Log(r2) - r1^2 * Log(r1) - 1 / 2 *((Lk - s)^2 - s^2))
H1 = H1 + 1 / 2 / Pai * (1 - s / Lk) * (h * Gum_12 + (Lk - s) * Log(r2) + s * Log(r1) - Lk)
End If
B_Inte_H1 = H1
End Function
External Function B_Inte_H2(Lk, r1, r2, Gam_12, h, s, Eps)
If r1 < Eps Then
H2 = Lk / 4 / Pai * (Log(Lk) - 1 / 2)
ElseIf r2 < Eps Then
H2 = Lk / 4 / Pai * (Log(Lk) - 3 / 2)
Else
H2 = 1 / 4 / Pai / Lk * (r2^2 * Log(r2) - r1^2 * Log(r1) - 1 / 2 *((Lk - s)^2 - s^2))
H2 = H2 + 1 / 2 / Pai * s / Lk * (h * Gum_12 + (Lk - s) * Log(r2) + s * Log(r1) - Lk)
End If
B_Inte_H2 = H2
End Function
以上の結果は、[計算部]と[外部手続き]のところへは、まだはめ込みません。[計算部]では、まだやる事があるからです(もぉ~、境界要素法って面倒くさいなぁ~(^^;))。
[境界要素法プログラムを設計する(境界積分サブルーティン:具体調査編)] [境界要素法]
[境界要素法プログラムを設計する(境界積分サブルーティン:具体調査編)]
1.最後はボトムアップになる
例は1個で十分です。
![]()
式(1)は、[内点方程式の積分公式(ラプラス型)]であげた、境界要素kの節点jのψjの係数を与える積分結果です(ずいぶん前のような気がしてますが(^^;))。特異点が要素節点に一致しない場合、境界方程式でもこの形の計算は必ずします。というかこういう場合の方が、圧倒的に多いです。
式中のLk,s,γ2,γ1,h,r2,r1が図-1から定められる積分パラメータです。このうちLk,s,h,r2,r1は単純に計算できます。例えばr1なら明らかに、
![]()
ですし、s,hはちょっと手がかかりますが、基本は(x0,y0),(x1,y1),(x2,y2)で係数が決まる2行2列の連立方程式を解くだけです。問題はγ2,γ1の与え方です。これは一見簡単そうに見えます。例えばγ1なら、
![]()
でいいんでないの?と。まず汎用言語の数学関数のAtn(tan-1の事)は、値域がふつう-π/2~π/2です。なんか鬱陶しそうだから、x1-x0とy1-y0の符号に注意して場合分けすれば、容易に0~2πをカバーできます。これでγ2-γ1>0は容易に計算できそうです。でも図-2のような場合はどうしますか?。
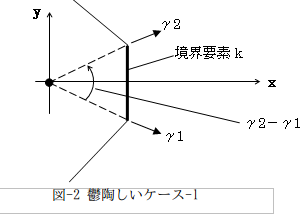
Atnを0~2πをカバーできるように改造したとしても、図-2では明らかにγ2<γ1でγ2-γ1<0です。しかし線積分(境界積分)は常に左回りなので、図中の角度矢印で示したように(左回り)、γ2-γ1>0でなければならず、しかも0~2πで表した|γ2-γ1|は本当の(γ2-γ1)と値が違います(2π大きい)。
では境界要素がx軸方向を横切る時だけ、2π引いて符号を反転させればOKなのか?というと、一般的には図-2への対処も必要です。
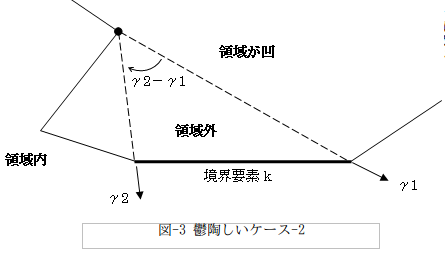
この場合は角度矢印が示すように(右回り)、γ2-γ1<0が正解です。図-3では0~2πの角度定義でたまたまγ2<γ1なので、そのままやって正解になりますが、図-2と3の複合ケースは?。・・・もう鬱陶しくてやってられません(^^;)。
つまりγ1とγ2は(βkも)単独で計算しては駄目なんですよ。あくまでγ1とγ2の角度差分を局所情報に基づいて計算する必要があります。こういう事は、普通の積分では起こりません。普通は図-1のように一周したら値は元に戻って問題ないはずです。これは積分結果がtan-1になるような正則でない関数を積分せざる得ない、特異積分を使っている境界要素法の特徴の反映です(複素積分を知ってる人なら、イメージできるはず)。そういう事情から、前回メインで大雑把に決めた関数の引数並びも、角度差分を与えるように変更する必要があります。
これはボトムアップです。このように最後はボトムアップになる事は多いです。トップダウンだけでは問題の個別状況の全ては把握できないからです。でも最後までボトムアップは我慢した方が、たいてい上手く行きます。
2.角度差分を計算するアルゴリズムを考える
一つだけ確かなのは、|γ2-γ1|はπ以下だ、という点です。|γ2-γ1|がπに成り得るのは、特異点が境界要素の中点上などにある場合なので、πを越える事はありません。そうすると格好の数学関数があります。Acos(cos-1)です。Acosの値域は、汎用言語においてたいてい0~πです。内積の定義から、
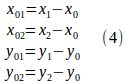
として、
![]()
なので
![]()
と求められます。|γ2-γ1|の符号は要するに、図-2,3の角度矢印の向きがわかれば良いので、ベクトル(x01,y01)と(x02,y02)の外積を利用する手があります。(x01,y01)はγ1方向,(x02,y02)はγ2方向のベクトルなので。(x01,y01)と(x02,y02)を3次元化して外積を取ると、
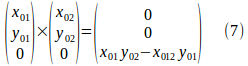
になります。(7)右辺のz成分が+なら左回りで、γ2-γ1=|γ2-γ1|。(7)右辺のz成分が-なら右回りで、γ2-γ1=-|γ2-γ1|と判定できます。ただし式(6)と(7)は小さすぎるr1やr2に対しては、結果が不安定になるのは目に見えています。本当にr1やr2が0なら、division by zeroエラーになります。なりますが、特異点が要素節点に一致する場合も、もともと扱うのでした。だとすればそういう特殊ケースは、特異点が要素節点に一致するケースに含めれば十分です。
3.特異点が要素節点に一致するケース
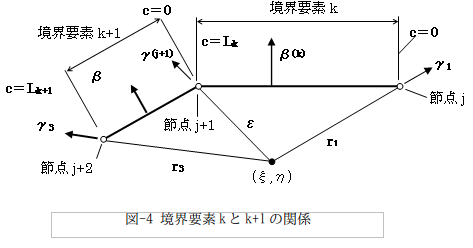
ここでもγ2-γ1の扱いが問題になります。[内点方程式から境界方程式へ(ラプラス型)]でFree Termの項は、次のように計算されました。

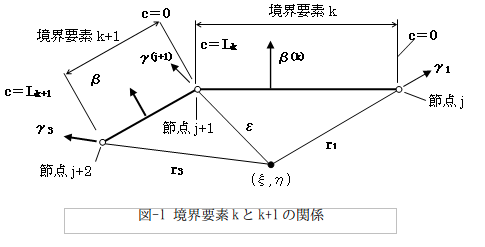
式(8)上段の1/2π×()内の1項目が要素k+1のγ2-γ1すなわち、図-4のγ3-γ(j+1)です。2項目は要素kのγ2-γ1すなわち、図-4のγ(j+1) -γ1です。ただしε→0の極限で考えてます。
でも待って下さい。ε→0の場合(特異点が要素節点に一致する場合)、どうやってγ(j+1) を与えれば良いんでしょう?。だって数値計算上はε=0なんですから。そしてすぐに気づくのは、特異点が要素節点に一致するケースでは、「個々の要素の境界積分値は、特異点の要素節点への近づき方に依存する!」という驚愕の事態が発覚します。もろな特異積分!。境界積分は結局、可積分でない?(^^;)。
・・・とけっこう猛烈に焦っちゃう訳ですが、式(8)下段では不定なγ(j+1)が引き算でキャンセルされて、「境界積分全体では近づき方に依存せず、値は一意に定まる」事になります。境界要素法は、こういう危ういところを持っています。ブレビアさんがなりふり構わず、コーシーの主値積分を持ち込んだ気持ちもわかりますよ(^^;)。
つまり足せばγ(j+1)は消えるのですから、逆に言えばなんでも良い訳です。例えば要素kで(x02,y02)=(1,0)とし、要素k+1でも(x01,y01)=(1,0)にするとか。共有節点でγの方法が揃ってればOKなはず。どうしてかと言うと特異積分値は、局所情報に基づいて計算する必要があるから。
特異点が要素節点に一致するケースでは、その点でγ1,γ2は(1,0)方向に取ると決定します。後で後悔するかも知れませんが(^^;)。
あと考えるべき事は、r1またはr2がどれくらい0に近かったら、0とみなすかです。これは【桁落ち誤差と丸め誤差はプログラマーの敵!】のところで書いたように、
http://nekodamashi-math.blog.so-net.ne.jp/archive/c2306081239-2
「問題のスケール規模」で決めるのが妥当と考えられます。r1,r2は特異点と要素節点の距離です。これに対応するスケール規模は明らかに、解析領域の大きさです。0判定Epsはどこで与えれば良いでしょう?。
手がかりはたいてい「実行者」と「妥当な実行タイミング」にあります。「実行者」の第一候補は[入力部]です。[入力部]のRoll(役割)は、解析領域という外部情報をセットし[計算部]へ渡す事です。Epsは解析領域の大きさで決まるので、これは外部情報のセットです(そして渡す)。
次に実行タイミングですが、Epsのセットは[計算部]の実行前に、事前に一回だけで十分です。[計算部]の実行前には、[入力部]の実行があります。「実行者」と「妥当な実行タイミング」が理想的に一致したので、[入力部]の中でEpsのセットを行います。セットの場所は、全ての入力が完了した後の方がなんか安心じゃないですか?。
[メモ欄]と[宣言部]はできれば一対一に対応させたいので、[メモ欄]の最後に「REM Eps:0判定,Eps0:0オーダー」を追加し、[宣言部]の最後には「REM Eps:0判定」と「Eps0 = 10^(-6) REM 0オーダー」のコードを追加します。コードの心は、解析領域の大きさの1/100万より小さい距離は0とみなすです。そして[入力部]の最後に、
REM 全ての入力完了
REM 解析領域のx方向幅とy方向幅を取得
x_Min = 10^10 REM x座標最小値初期化
x_Max = -10^10 REM x座標最大値初期化
y_Min = 10^10 REM y座標最小値初期化
y_Max = -10^10 REM y座標最大値初期化
For j = 1 to BN_Count
h = BN(j, 1) REM j節点のx座標
If h < x_Min Then
x_Min = h
End If
If x_Max < h Then
x_Max = h
End If
h = BN(j, 2) REM j節点のy座標
If h < y_Min Then
y_Min = h
End If
If y_Max < h Then
y_Max = h
End If
Next j
x_Width = x_Max - x_Min REM 解析領域のx方向幅
y_Width = y_Max - y_Min REM 解析領域のy方向幅
REM 0判定距離をセット
If x_Width < y_Width Then
Eps = y_Width * Eps0
Else
Eps = x_Width * Eps0
End If
このEpsの与え方は、解析領域の最大幅をスケール規模とするやり方です。これでは駄目な場合ももちろんあり得ますが、とりあえず(^^;)。今回は[メモ欄][宣言部][入力部]のみあげます。[計算部]は、引数並びから検討し直す必要があるとわかったので。
ところでもう一個忘れてました。式(1)を見ると、定数πも必要です。これも[メモ欄]と[宣言部]に追加しておきます。
※ 後で調べてみたら、MAX関数とMIN関数と定数PIが組み込みになってました。まぁ~、好きにして下さい(^^;)。
REM B_Count:境界要素数
REM EN_B(k,2):境界要素-節点対応表,k=1~B_Count
REM (k,1):要素kの始端の節点No.,(k,2):終端の節点No.
REM R_Count:領域要素数
REM EN_R(k,4):領域要素-節点対応表,k=1~R_Count
REM (k,j),j=1~4:jに従って要素kの要素節点No.を左回りに格納
REM BN_Count:境界節点数
REM BN(j,2):境界節点座標,j=1~BN_Count,(j,1):節点jのx座標,(j,2):y座標
REM RN_Count:領域節点数
REM RN(j,2):領域節点座標,j=1~RN_Count,(j,1):節点jのx座標,(j,2):y座標
REM BN_BP(j,2):節点の境界条件の有無,j=1~BN_Count
REM (j,1):節点jのψjが既知なら1、そうでないなら0
REM (j,2):節点jのqjが既知なら1、そうでないなら0
REM BN_BV(j,2):境界条件の値,j=1~BN_Count
REM (j,1):節点jのψjに与える値
REM (j,2):節点jのqjに与える値
REM z(i):未知ベクトル,i=1~2*BN_Count
REM BN_Z(j,2):節点-未知数対応表,j=1~BN_Count
REM (j,1):ψjのzの中の位置,(j,2):qjのzの中の位置
REM 節点j→ψj→z(j),節点j→qj→z(BN_Count+j)
REM A(i, j):全体係数マトリックス、i,j=1~2*BN_Count
REM Eps:0判定
REM Eps0:0オーダー
REM Pai:π
REM [宣言部]
REM 配列寸法の上限は1000
REM B_Count:境界要素数
REM R_Count:領域要素数
Dim EN_B(1000,2) REM 境界要素-節点対応表,k=1~B_Count
Dim EN_R(1000,4) REM 領域要素-節点対応表,k=1~R_Count
REM BN_Count:境界節点数
REM RN_Count:領域節点数
Dim BN(1000,2) REM 境界節点座標,j=1~BN_Count
Dim RN(1000,2) REM 領域節点座標,j=1~RN_Count
Dim BN_BP(1000,2) REM 節点の境界条件の有無,j=1~BN_Count
Dim BN_BV(1000,2) REM 境界条件の値,j=1~BN_Count
Dim BN_Z(1000,2) REM 節点-未知数対応表,j=1~BN_Count
Dim z(1000) REM 未知ベクトル,i=1~2*BN_Count
Dim A(1000, 1000) REM 全体係数マトリックス、i,j=1~2*BN_Count
REM Eps:0判定
Eps0 = 10^(-6) REM 0オーダー
Pai = Acos(-1) REM π:Fortranになじんだ人なら、懐かしくて泣いちゃう式(^^)
REM [入力部]
REM境界要素数B_Countと領域要素数R_Countは、事前に与えられると仮定する。
REM 境界要素と領域要素データは、要素ごとに節点番号が与えられると仮定する。
REM 与えられる節点番号は、左回りに順序付けられたものが与えられると仮定する。
REM 境界要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、境界要素-節点対応表EN_B(k,2)をセット
For k = 1 to B_Count
EN_B(k,1) = ?
EN_B(k,2) = ?
Next k
REM 領域要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、領域要素-節点対応表EN_R(k,4)をセット
For k = 1 to R_Count
For j = 1 to 4
EN_R(k,j) = ?
Next j
Next k
REM境界節点数BN_Countと領域節点数RN_Countは、事前に与えられると仮定する。
REM 境界節点を節点番号jで読み込むLoop
REM Loop内で境界節点座標を読み、BN(j,2)をセット
For j = 1 to BN_Count
BN(j,1) = ?
BN(j,2) = ?
Next j
REM 領域節点を節点番号jで読み込むLoop
REM Loop内で領域節点座標を読み、RN(j,2)をセット
For j = 1 to RN_Count
RN(j,1) = ?
RN(j,2) = ?
Next j
REM 境界条件の場所を節点番号jで読み込むLoop
REM Loop内で節点jの境界条件の有無を読み、BN_BP(j,2)をセット
For j = 1 to BN_Count
BN_BP(j,1) = ?
BN_BP(j,2) = ?
Next j
REM 境界条件の値を節点番号jで読み込むLoop
REM Loop内で節点jの境界条件の値を読み、BN_BV(j,2)をセット
For j = 1 to BN_Count
BN_BV(j,1) = ?
BN_BV(j,2) = ?
Next j
REM 節点番号jのLoopで、節点-未知数対応表BN_Z(j,2)をセット
REM (j,1):ψjのzの中の位置,(j,2):qjのzの中の位置
REM 対応は、節点j→ψj→z(j),節点j→qj→z(BN_Count+j)
For j = 1 to BN_Count
BN_Z(j,1) = j
BN_Z(j,2) = BN_Count + j
Next j
REM 全ての入力完了 **********************************************
REM 解析領域のx方向幅とy方向幅を取得
x_Min = 10^10 REM x座標最小値初期化
x_Max = -10^10 REM x座標最大値初期化
y_Min = 10^10 REM y座標最小値初期化
y_Max = -10^10 REM y座標最大値初期化
For j = 1 to BN_Count
h = BN(j, 1) REM j節点のx座標
If h < x_Min Then
x_Min = h
End If
If x_Max < h Then
x_Max = h
End If
h = BN(j, 2) REM j節点のy座標
If h < y_Min Then
y_Min = h
End If
If y_Max < h Then
y_Max = h
End If
Next j
x_Width = x_Max - x_Min REM 解析領域のx方向幅
y_Width = y_Max - y_Min REM 解析領域のy方向幅
REM 0判定距離をセット
If x_Width < y_Width Then
Eps = y_Width * Eps0
Else
Eps = x_Width * Eps0
End If
[境界要素法プログラムを設計する(境界積分サブルーティン:事前調査編)] [境界要素法]
[境界要素法プログラムを設計する(境界積分サブルーティン:事前調査編)]
1.再利用性を考える
トップダウンでやってくると(やって来たつもりです(^^;))、サブルーティンの具体化の際には、その全体仕様として考えるべきところはもう、前回の3)再利用性くらいしか残らないはずです。どういうケースで使い回される可能性があるか?。
一要素の境界積分値は、特異点座標と要素端の節点座標で決まりました。また境界積分は境界方程式と、いまだ未考慮の内点方程式で使われます。境界方程式のケースでは、特異点座標と要素節点座標が一致する場合としない場合があり、それに応じて処理を変える必要がありました。一方、内点方程式のケースでは特異点と節点は必ず一致しません。よって境界方程式のケースで考えとけば、内点方程式のケースをカバーできると思われます。
他に境界積分値が使われる場面はあるでしょうか?。ないと思われます。従って再利用性を考慮した結果は、境界方程式用の境界積分サブルーティンだけで良い、となります。
2.具体的使用法を考える
サブルーティンとは小さくても自作ライブラリです。なのでその覚悟でやるべきと自分は思ってます(オブジェクト指向採用の場合はもっとそう)。最初に考えるのは、その呼び出し方(←トップダウン,トップダウンとお呪い(^^))。それが使われるのは、[境界要素法プログラムを設計する(計算部と出力部の実装)]の「境界要素番号kで境界積分を行うLoop」の中の、
REM (x0,y0),(x1,y1),(x2,y2)から、要素kの境界積分値を計算
REM ψj1に関する結果をB1,qj1に関する結果をH1で表す
REM ψj2に関する結果をB2,qj2に関する結果をH2で表す
という部分でした。要するに境界積分サブルーティンは、上記の値:B1,B2,H1,H2を与えるものです。そうするとサブルーティン形式より関数の方がスマートです。
B1 = B_Inte_B1(x0,y0,x1,y1,x2,y2)
B2 = B_Inte_B2(x0,y0,x1,y1,x2,y2)
H1 = B_Inte_H1(x0,y0,x1,y1,x2,y2)
H2 = B_Inte_H2(x0,y0,x1,y1,x2,y2)
といった感じでしょうか?。
ここで関数を4つも用意するなら、一つのサブルーティンで、
Call B_Inte(x0,y0,x1,y1,x2,y2, B1, B2, H1, H2)
とやった方がスマートでは?、という意見もあると思いますが、引数が10個もあるので嫌なのだ。(x0,y0),(x1,y1),(x2,y2)の部分は配列にして渡せばいいじゃん、という意見もあるが、新しい配列宣言とそれへの値代入がメインに増えるから嫌なのだ。
だったら、節点座標は[入力部]で最初から配列として与えられるんだから、
Call B_Inte(BN(i, 1),BN(j1, 1),BN(j2, 1), B1, B2, H1, H2)
とすれば良いじゃん!。後で見たとき配列BNの構成を勘違いしそうなので、やっぱり嫌なのだ。だいたいこっちの方が、引数並びの字数も多いじゃねぇ~か。それにメインの作業は、やる事を明示的にコード化したいのだ。だから関数名くらいケチケチしないのだ。
※これはプログラマーの趣味です。まぁ~、こんなもんです(^^;)。
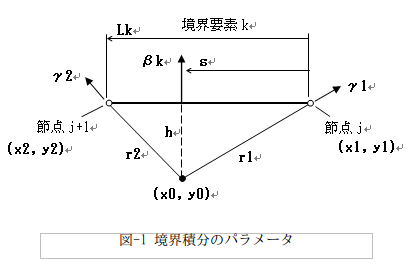
ところが境界積分は、次図のパラメータを定義すると便利なのでした。
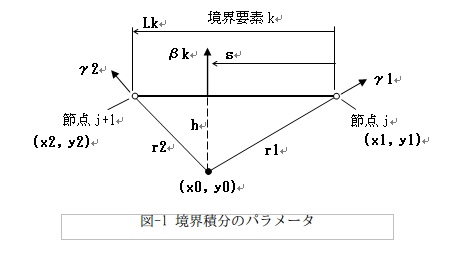
境界要素kの外法線方向βkはBeta_kで、r1とr2の方向γ1,γ2はGamm_1,Gamm_2で表します。
Lk = Length(x1,y1,x2,y2)
Beta_k = Angle(x2 - x1, y2 - y1, Lk)
r1 = Length(x0,y0,x1,y1)
r2 = Length(x0,y0,x2,y2)
Gamm_1 = Angle(x1 - x0, y1 - y0, r1)
Gamm_2 = Angle(x2 - x0, y2 - y0, r2)
h = Normal_Length(x2 - x1, y2 - y1, x0,y0)
s = Normal_Foot(x2 - x1, y2 - y1, x0,y0, h)
という関数で積分パラメータは計算できそうです。関数でやると決めたので、関数名はケチりません。また関数Length,Angle,Normal_Length,Normal_Footの引数並びから判断し、内部で重複した計算はほぼ起こらないと思われるので、とりあえずこれらでOKとします。従って、
B1 = B_Inte_B1(Lk, r1, r2, Beta_k, Gamm_1, Gamm_2, h, s)
B2 = B_Inte_B2(Lk, r1, r2, Beta_k, Gamm_1, Gamm_2, h, s)
H1 = B_Inte_H1(Lk, r1, r2, Beta_k, Gamm_1, Gamm_2, h, s)
H2 = B_Inte_H2(Lk, r1, r2, Beta_k, Gamm_1, Gamm_2, h, s)
です。
とここで・・・。
B1,B2,H1,H2を与える関数の引数は結局ずいぶん長いじゃないか!。それに関数を8行もメインに追加しやがって、今まで長い引数並びは嫌だのメインの行数は増やしたくないだの、さんざん言いやがったくせに、いいのかよ?。
そうなんですが、ここは「いいんです!」とシレっと言います(^^;)。メインの作業を明示的にコード化し、明確にしたからです。図-1と関数Length~Normal_Footの意図を理解できれば、ほぼ間違う事はないからです(←嘘です。けっこう気軽に間違います(^^;))。
本当は図-1も、関数Length~Normal_Footの関数定義も、その意図とともに[メモ欄]に突っ込んでおきたいところなんです。だから本当は、そういう設計思想をまとめたものを独立した文書として持つべきなんですよ。それを常に参照しつつプログラミングを行い、必要に応じて文書の加筆・修訂正も行う。そうすれば開発が終わった暁には、製品と仕様書が同時にあがっています。理想的に上手く行けば取説も(^^)。
それが本当の意味でのスパイラルでありアジャイル開発だと思います。そういうのを自分は、アプリケーション構造設計書と勝手に呼んでます。最初からここまで書いてきた事は(およびこの先も含めて)、口語体で書かれたアプリケーション構造設計書だと自分は思ってます。
ところで具体的実装(具体的調査含む)をちょっとやってみると、ここでの想定の不味さがあっさりと発覚します。それは境界要素法の数学的特異性(危うさ?)に由来するものなので、今回はここでやめます。
[境界要素法プログラムを設計する(境界積分サブルーテイン:策定編)] [境界要素法]
[境界要素法プログラムを設計する(境界積分サブルーテイン:策定編)]
1.サブルーティンは必要か?
世の中には、何でもかんでもサブルーティンにすれば良いと思ってる人がけっこういますが、自分の意見は違います。メインルーティンの作業をサブルーティン化すれば、確かにメインは綺麗に整理されてプログラムのフローがわかりやすくなります。しかし代償もあります。それは具体的な作業コードが隠蔽化(カプセル化)されて、可読性(読み解きやすさ)が悪くなるケースもあり得るからです。
特に大規模プログラムでは何10~何100というサブルーティンが現れ(大規模だからしゃーないんだけど)、こっちのファイルを読みあっちのファイル読んで、そっちのページを・・・とやってると、最弱マシンである人間は、それだけでバグ化します(^^;)。こういう場合は、メインの作業フローを組み直すべきなんですが、では次のような例はどうでしょう?。
よくサブルーティンは引数付きが推奨されます。ローカル変数が使えるので、変数競合を避けられるからです。最強マシンであるPCが、最弱マシンである人間のミスから、その最弱マシンを自動で守ってくれます。
メイン冒頭でxの値を評価し、その評価によって計算の行く末を決める、計算初期値yの値が変わるとします。
If x < 0 Then
y = 0
ElseIf (0 <= x) And (x < 1) Then
y = 1
Else
y = 2
End If
REM yを使った計算
これはサブルーティン化すべきでしょうか?。するとしたら、こんな感じになりそうです。
External Function y_Setter(x)
If x < 0 Then
y = 0
ElseIf (0 <= x) And (x < 1) Then
y = 1
Else
y = 2
End If
y_Setter = y
End Function
If x < 0 Then
y = 0
ElseIf (0 <= x) And (x < 1) Then
y = 1
Else
y = 2
End If
REM yを使った計算
・・・と非常にすっきり(^^)。ところが入力仕様が変わり、yのケース分けが1個追加され、しかもケース境界も可変になる事がわかりました。それにともなって「yを使った計算」も変更されます。こうなると、
External Function y_Setter(x)
If x < 0 Then
y = 0
ElseIf (0 <= x) And (x < 1) Then
y = 1
Else
y = 2
End If
y_Setter = y
End Function
メインの側は、
Declare External Function y_Setter
y = y_Setter(x)
REM yを使った計算
だいたいこの辺りからPMは、PG(プログラマー)の恨みを買い出します(^^;)。
y = y_Setter(x, z1, z2, z3) REM z1~z3はケース分けの境界値
REM yを使った計算_変更1
External Function y_Setter(x, z1, z2, z3)
If x < z1 Then
y = 0
ElseIf (0 <= z1) And (x < z2) Then
y = 1
ElseIf (0 <= z2) And (x < z3) Then
y = 2
Else
y = 3
End If
y_Setter = y
End Function
事態はさらに最悪の方向へ向かいます。「開発が終わるまで入力仕様の変更は続き、ケース分けは何ケースになるかわからない。それに対処できるようにしといてくれ」。・・・頭に血が上ったPGは、こう叫びます。
「わかった。配列で渡すようにする。後で汚いとかコードが重いとか、文句言うなよ!」
引数付きサブルーティンは確かに推奨されるべきものです。でも、入力仕様の変更に非常に弱いという欠点も持ちます。だからやめなさいって、そんなもん。自分ならメインで単にこうします。
If x < z1 Then
y = y0
ElseIf (0 <= z1) And (x < z2) Then
y = y1
ElseIf (0 <= z2) And (x < z3) Then
y = y2
Else
y = y3
End If
REM yを使った計算_変更2
REM ElseIfブロックは、何個でもコピーして増やせる!
もう一つは、引数並びが重く複雑なサブルーティンは内容も複雑な訳です。しかもサブルーティン化したためにコードが隠蔽され、メインと並べて一目で見渡せなくなります。最弱マシンはそこで、必ず何かを見落とします。バグ特定がしずらいため、それはバグの連鎖反応も招きかねません。
でもテスト技術者(TE)って、こういうコードが嫌いなような印象を受けます(規格物好き?)。確かに綺麗なコードの方が、テストしやすいですもんね。「何でサブ化しない?」ってけっこう言われました(^^;)。
PG「だって仕方ねぇ~だろう。PMの野郎が仕様をどんどん変えるんだから」
TE「それとコードの可読性は別だ。サブ化しないから可読性が悪い」
PG「悪いだと?。上から順番に読めば、必ずわかるコードのどこが悪い」
TE「メインに1万行も書きやがって、この馬鹿ものがぁ~!」
PG「うるせぇ~!。順番に1万行も読めない奴は、PGでもTEでもねぇ~!」
PM「開発の最終段階でサブ化したら?」
PGとTE「・・・・・・」
2.境界要素法プログラムは?
で、境界要素法プログラムではどうでしょう?。とりあえず問題の部分は、
REM (x0,y0),(x1,y1),(x2,y2)から、要素kの境界積分値を計算
でした。ここで(x0,y0)は特異点座標、(x1,y1)と(x2,y2)は一つの境界要素kの端点座標です。これらは入力部で既に確定しています。という事は、仕様変更はほとんどなさそうです。
・・・ではサブ化しますか。でも自分の考えでは、これだけでは弱いと思います。境界要素法プログラムの[計算部]をサブ化せずに全部ベタ書きしても、1000行くらいだと思います。さっきのお馬鹿PGだったら「ベタ書きしろぉ~!」というでしょう。1000行くらいなら全体を一気に見渡せると思えるからです。なぜコードを隠蔽して、見にくくするのか?。もっと強力な理由が必要です。設計における方針決定には、明白な根拠があるべきです。
「境界要素番号kで境界積分を行うLoop」が動的過程だからです。前回の該当部分を見て下さい。自分は十分に長いLoopだと思います。その最大の理由は、要素-節点対応表を使って積分値の重ね合わせをやってるからです。つまりこのLoopは一種の漸化式なんですよ。漸化式って短くても、すぐ訳わかんなくなりますよね?(^^;)。そういう部分は出来るだけ綺麗に見やすくしとくべきだ、と思うからです。境界積分値を計算する、サブルーティンを作ると方針決定します。
これは、
1) 動的過程を制御するメタな静的構造(今はLoop)の可読性を上げて確保する.
事でもあります。ほとんど意識されませんが、サブルーティンを用いる最も大きな理由の一つが上記だと自分は思います(コード自体は短くても)。y_Setterはそういうものではありませんでした。
あとサブルーティンを用いる一般的理由としては、当然ながら、
2) メインが長すぎて一気に読めない(1万行は多すぎる(^^;)).
3) 再利用性を考えた.
などです。y_Setterは、2),3)いずれにも該当しません。
3)は(オブジェクト指向も含めて)サブルーティン化の大きな理由とされますが、じつはバグの発生頻度とトレードオフの関係にあります。
一般にコードは書けば書くほどバグ確率は比例して増加します。再利用すれば一回しか書かないので、良さそうに思えます。しかしコードは隠蔽されるので、潜在バグの発生確率が上がります。それに気づかぬまま潜在バグが発覚すると、今度はシステム全体で大被害です。大抵そこら中で使い回すからですよ。大被害が出るとバグの場所はわかりやすいですけれど、運用段階に入ってた銀行のシステムなんかだと、わかりやすいでは済みません(^^;)。一番困るのが、運用段階に入ったサブルーティン間の競合です。
以上は全て人間の都合です。機械にとってはどうでも良い事です。なので2)などは、人間の限界を認めた話です。人間原理最優先で行きましょう(^^)。人間原理最優先なので、以後サブルーティンと関数にはローカル変数を持てる外部手続きのみ用います。タフな機械に守ってもらいます。
[境界要素法プログラムを設計する(基本のGauss掃き出し法)] [境界要素法]
[境界要素法プログラムを設計する(基本のGauss掃き出し法)]
1.Gauss掃き出し法の標準構成
前回の[外部手続き]の最後に、
REM Gauss掃き出し法 **********************************************
External Sub Gauss_0(A, z, n, Zero_Order, Return_Code)
REM まだ何にもしない
End Sub
という、よくわからんものがくっついてたはずです(^^)。今回はこの中身をつくろうという話です。Gauss掃き出し法は連立一次方程式を解く、標準解法です。なので別に境界要素法でなくても良いのですが(^^;)。
Gauss_0の引数Aは、解くべき連立一次方程式の係数マトリックスを表す配列,zはGauss_0が呼ばれた時は連立一次方程式の既知ベクトル(配列)で、Gauss_0の処理が終わると解ベクトルになっています。nは未知数の数,Zero_Orderは後述するピボット選択で使用する0判定オーダーを表す整数,Return_Codeは計算終了状態をGauss_0の外部へ伝えるために用意した引数です。
標準解法なので、数値計算業界(?)の業界標準みたいな構成があります。こういう構成です。
External Sub Gauss_0(A, z, n, Zero_Order, Return_Code)
External Sub Scaling
External Sub Foward_Eliminate
External Sub Back_Sub
REM スケーリング
Call Scaling(A, z, n, Return_Code)
If Return_Code <> 0 Then
Return
End If
REM 前進消去
Call Foward_Eliminate(A, z, n, Zero_Order, Return_Code)
If Return_Code <> 0 Then
Return
End If
REM 後退代入
Call Back_Sub(A, z, n)
End Sub
とりあえず、If Return_Code <> 0 ThenのIfブロックはおいといて、REM文の後のサブルーティン呼び出しに注目です。呼ばれるサブルーティンは、スケーリング(Scaling),前進消去(Foward Elimination),後退代入(Back Substitution)を行います。このうち前進消去と後退代入の意味がわからない人は、
ネコ先生の記事を読もう!。
2.スケーリング
スケーリングは桁落ち誤差対策です。連立一次方程式の係数マトリックスを表す配列Aは、ふつう倍精度浮動小数点実数で宣言されますが、倍精度浮動小数点実数型の公称有効数字は16桁と決まっています(国際規格)。以下は極端な例ですが、次の2元連立一次方程式を考えます。
![]()
上記を解くと、(2)-(1)で、
![]()
(2')より、
![]()
なので、(3)を(1)に代入し、
![]()
となります。(3),(4)より厳密解は、ほとんどx=2,y=1である事がわかります。数値計算には必ず数値誤差が憑きもの(?(^^;))です。なので例え数値誤差が憑いたとしても、x=2,y=1程度の近似解は出るようにしたい訳です。
同じ事をコンピューターにやらせると、既に(2')の段階でコンピューター内部では-(1+1020) → -1020,1-1020 → -1020という現象が起きてしまいます。有効数字が16桁しかないからです。
すると(3)でy=1となり、それを(1)に代入するとx=0となって全くお話になりません。何故ならx=0,y=1を(2)に代入すると、誤差がありとしても想定外の、-1=1という不当過ぎるな結果になるからです。
一方、
![]()
としてもOKなはずです。(1')は(1)の両辺を1020で割っただけのもの。ここで(2)-(1')をやるために、(1')のxの係数を1にしようとして、(1')を1020倍したら馬鹿です。(1)と(2)の状態に戻るので。(1')-10-20×(2)を試してみましょう。下から上を引いた方が考えやすいので行交換を行い、
![]()
として(1')-10-20×(2)を行うと、
![]()
(1")より、
![]()
と(3)と同じものが得られますが、これを(2)に代入すれば、x=2が得られます。
だまされたような気持ちですか?(^^)。でもこのトリックは正しいんです。理由はなんでしょう?。連立方程式の「構造」に注目します。(1)と(1')を比べると、条件(1')ではxの寄与は非常に小さいとわかります。無視してもいいくらいです。無視するとy=1です。それを(2)に代入しx=2。(1)と(1')は同じ条件のはずなのに・・・。
以上を強引にまとめると、こうなります。
大きすぎる数値で桁落ちが起こるより、非常に小さい数値で桁落ちが起こった方がましだ!。
そして桁落ちは必ず起こる!。
理由は連立方程式の中で微小な係数しか持たない部分は、最初から無視しても構造的に被害小だからです。いいかえれば、ちゃんとした近似構造を解いた。
しかし連立方程式の各条件は、何倍しても理屈の上では同じ条件。本当は寄与が少ない部分も、生の数値ではそう見えないかも知れない。よって寄与が少ないと見分けるためには、連立方程式の各行の数値桁数を揃えればいい、という話になります。そのために、連立方程式の各行を各行の絶対値最大成分の値で割り、各行の最大係数を1に揃える作業を、スケーリングと言います(← 一種のスケール規模問題です)。
スケーリングを行うと、連立方程式の数値的安定性は格段に向上します。でも数値誤差は憑き物(^^;)。弊害もあります。ほとんど特異な連立方程式(解けちゃいけない)が、安定に解けてとんでもない答えが出る場合もあります。そして人間は馬鹿だから、その答えを信じます(^^;)。
ところで(1')(2)を(2)(1')にしたような行交換を、機械は自動で出来るものでしょうか?。それは次のピボット選択と関連します。
ところで桁落ち誤差の意味がわからない人は、ネコ先生の記事を読もう!。
3.ピボット選択
ピボット選択は基本的に丸め誤差対策です。掃き出し中の連立一次方程式の係数配列は、概ね下図のようになります。灰色の部分は掃き出し完了ブロックで、成分は全て0です。Active行,Active列に囲われた部分が、これからs回目の掃き出しを行おうという、未処理ブロックになります。Active行,Active列の交点を、特にピボット(Pivot:枢軸)と言います。
掃き出し処理は、Active列のs+1行~n行成分を0にすれば完了です。そのためにまず、Active行をピボットassで割り、被処理行の頭の値as+2 sなどをActive行にかけて、非処理行から引きます。「/」を使う時には、常に割る数が0でないかどうかのチェックが必要です。
assがたまたま0という事はあり得ます。でもActive列の中には非零成分がたぶんあります。そこでActive列のs行~n行を検索し、最初に見つかった0でないaksを持つ行をActive行(s行)と交換し、k行目をActive行とすればOKです。もしActive列に非零成分がなければ、特異行列です。答えがでちゃいけません。そこで処理を中止します。
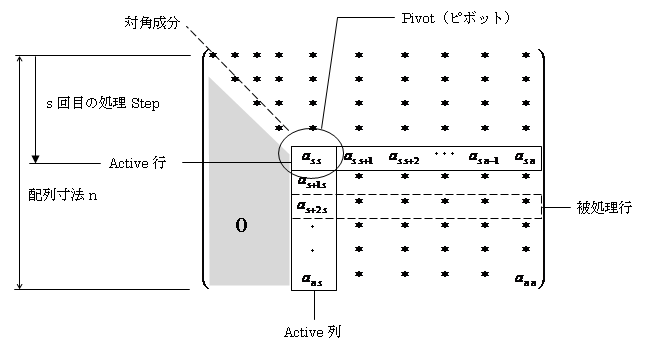
でも数値誤差は憑き物。本当は0なんだけど0に近いが0になってない数値はきっと、Active列にもごろごろしてます(^^;)。どれくらい小さければ0とみなすか?。要するに閾値Epsはどれくらいか?。これは問題のスケール規模で決まります。
係数配列の数値は平均的に非常に大きい場合もあるし、逆もありえます。両方で同じEpsを使っては計算精度なんか保証されません。でもスケーリングしたのでした。各行の最大成分は初期状態で必ず1です。スケール規模は「1」です。「1」を基準にEpsを決定できます(^^)。ここで引数Zero_Order登場です。Active列の非零成分検索で、絶対値が Eps=1.0 * 10^(-Zero_Order) 未満のものは0とみなします。自分は経験的にZero_Order=8を使います。
でも非零という条件だけでいいのでしょうか?。係数配列は初期状態においてすら、すでに各数値には丸め誤差δが含まれます。コンピューターの数値には、有限の有効桁数しかないからです。コンピューターの中の方程式とは、要するに最初から近似方程式なんですよ。数値誤差は数値計算の憑き物!(^^;)。
真の値がaij+δならば、それをピボットassで割る事により、丸め誤差の影響はδ/assになります。小さすぎるassで割ると、丸め誤差の影響は拡大します。もう一つ困るのはassが微小だと、スケーリングのところでやった(1')を、わざわざ(1)に戻すような事まで起きる可能性がある事です。せっかくスケーリングしたのに。
なので、Active列の絶対値最大成分を持つ行をActive行と交換します。これがピボット選択(行ピボット選択)です。あれっ、(1')と(2)の行交換が自動で出来ちゃった・・・(^^)。
スケーリングとピボット選択をセットで使うと、概ね6桁くらいの有効数字を数値誤差の影響から救えます。10^6=1,000,000なので、馬鹿にならない数字です。
ところで丸め誤差の意味がわからない人は、ネコ先生の記事を読もう!。
REM スケーリング
External Sub Scaling(A, z, n, Return_Code)
For i = 1 to n
Ma = 0
jj = 0
REM 行の絶対値最大成分を検索
For j = 1 to n
h = Abs(A(i, j))
If Ma < h Then
Ma = h
jj = j
End If
Next j
REM 行が0だったら処理中止
If Ma = 0 Then
Return_Code = 1
Return
End if
REM 絶対値最大成分で行を割り規格化
h = A(i, jj)
z(i) = z(i) / h
For j = 1 to n
A(i, j) = A(i, j) / h
Next j
Next i
Return_Code = 0
End Sub
REM 前進消去
External Sub Foward_Eliminate(A, z, n, Zero_Order, Return_Code)
REM 0判定値セット
Eps = 10^(- Zero_Order)
For i = 1 to n
REM Pivot検索
Ma = 0
ii = i
For k = i to n
h = Abs(A(k, i))
If Ma < h Then
Ma = h
ii = k
End If
Next k
REM Pivot候補がEps未満だったら処理中止
If Ma < Eps Then
Return_Code = 2
Return
End if
REM 行選択Pivot
If ii <> i Then
P1 = z(i)
P2 = z(ii)
z(i) = P2
z(ii) = P1
For j = i to n
P1 = A(i, j)
P2 = A(ii, j)
A(i, j) = P2
A(ii, j) = P1
Next j
REM 掃き出し処理
h = A(i, i) REM Pivotセット
z(i) = z(i) / h REM 既知ベクトルのActive行を規格化
For j = i + 1 to n REM 係数配列のActive行を規格化
A(i, j) = A(i, j) / h
Next j
For k = i + 1 to n REM 掃き出し
h = A(k, i) REM 非処理行の頭をセット
If h <> 0 Then REM Fillin Skip
z(k) = z(k) - h * z(i) REM 既知ベクトルの掃き出し
For j = i + 1 to n REM 係数配列の被処理行を掃き出し
A(k, j) = A(k, j) - h * A(i, j)
Next j
End If
Next k
Next i
Return_Code = 0
End Sub
REM 後退代入
External Sub Back_Sub(A, z, n)
For i = n to 1 Skip -1
h = 0
For j = n to i + 1 Skip -1
h = h - A(i, j) * z(j)
Next j
z(i) = h
Next i
End Sub
(執筆 ddt²さん)
[境界要素法プログラムを設計する(計算部と出力部の実装)] [境界要素法]
1.実行者は要素だ。そして常にトップダウンだ!
入力部の実装によって、計算に必要な全ての情報はセットされました(されたはず(^^;))。次にやる事は、それらを利用して具体的な計算ルーティンを書く事です。計算部(ビジネスルール層)は、アプリケーションの中で最も動的な部分で、書いてて最も面白い部分でもありますが、バグの温床にもなります。最も動的だからです。
人間は動的対象を見るとすぐに幻惑され、目算を見失います。なので動的過程を動かす、メタな静的構造を保持しておくのが安全です。それは多くの場合、動的過程の制御部分ですが、これとトップダウン思考を重ねると、制御部分は「実行者」になります。「実行者」は「要素」でした。
[計算部]の冒頭にこうあります。
REM 境界要素番号kで境界積分を行うLoop
REM 要素番号kからEN_B(k,2)に従い節点を特定し、要素ごとに境界積分を実行
REM 上記結果に基づき、係数マトリックスBとHを作成
要するにLoopを作りますが、設計の基本は常トップダウンです。よってLoopは、最外殻から書き始めるのが基本です。そうして動的過程を動かすメタな静的構造を確定させると、そこに「実行者」がすんなり納まります。要するに、境界要素を走るLoopを最初に書くべきだ、という事です。
REM 境界要素番号kで境界積分を行うLoop
For k = 1 to B_Count
REM 要素番号kからEN_B(k,2)に従い節点を特定し、要素ごとに境界積分を実行
REM 上記結果に基づき、係数マトリックスBとHを作成
Next k
ところで上記を見て、何か気づきませんか?。目標とする方程式系は、

そこで慌てて[メモ欄]を見返すと、定義してない!。[メモ欄]と[宣言部]は一対一に対応してるので、要はAを宣言してないって事です。そこでさらに慌てて、[メモ欄]のz(i)に関する部分の後に、
REM A(i, j):全体係数マトリックス、i,j=1~2*BN_Count
と書き加え同時に、[宣言部]の同じ場所に、
Dim A(1000, 1000) REM 全体係数マトリックス、i,j=1~2*BN_Count
を追加します。i,j=1~2*BN_Countなのは、z(i),i=1~2*BN_Countだからです。
実務でもこんな事は良くあるのだ!。じっさい忘れてたし(^^;)。でもトップダウン方式だから被害は最小限と思えませんか?。これがボトムアップだったら、既に変数Aは別の目的で使われてて2重宣言が起こり、いや2度ある事は3度ある・・・3重宣言が起こり、3つあるAの内の2つをA1とA2に書き変える事にして、沢山の行のAを一つ一つ判断しながらA1やA2に書き変え、そこでまた判断ミスしてそれがまたバグの温床となり、・・・で訳わかんなくなってバグの連鎖反応が、・・・などと屁理屈をこねるのであった(^^;)。
全体係数マトリックスAを導入したおかげで、さらにもう一つの大事に気づきます。思い起こせば境界積分の値は、特異点の位置によって変わるのでした。マトリックスAは境界方程式に対応するので、いま考える特異点は境界節点のどれかと一致します。その番号(特異点番号)をiとした時、iはAに含まれるBとHの行番号なのでした。つまり、
REM 境界要素番号kで境界積分を行うLoop
For i = 1 to BN_Count
REM 特異点番号iの節点iを特定
For k = 1 to B_Count
REM 要素番号kからEN_B(k,2)に従い節点を特定し、要素ごとに境界積分を実行
REM 上記結果に基づき、係数マトリックスBとHを作成
Next k
Next i
としなければならない訳です。まぁ~、こういう事も良くありますって・・・(^^;)。
次にもう少し「境界要素番号kで境界積分を行うLoop」を具体化します。入力部の情報をいかに使うべきかを、自分にわからせるためにです。
REM 境界要素番号kで境界積分を行うLoop
For i = 1 to BN_Count
REM 特異点番号iの節点iを特定
x0 = BN(i, 1) REM 節点iの(x,y)座標
y0 = BN(i, 2)
For k = 1 to B_Count
REM 要素番号kからEN_B(k,2)に従い節点を特定し、要素ごとに境界積分を実行
j1 = EN_B(k,1) REM 要素kの始端の節点番号
j2 = EN_B(k,2) REM 要素kの終端の節点番号
x1 = BN(j1, 1) REM 節点j1の(x,y)座標
y1 = BN(j1, 2)
x2 = BN(j2, 1) REM 節点j2の(x,y)座標
y2 = BN(j2, 2)
REM (x0,y0),(x1,y1),(x2,y2)から、要素kの境界積分値を計算
REM ψj1に関する結果をB1,qj1に関する結果をH1で表す
REM ψj2に関する結果をB2,qj2に関する結果をH2で表す
REM 上記結果に基づき、係数マトリックスBとHを作成
jj1 = BN_Z(j1,1) REM ψj1の解ベクトルzの中での位置
jjj1 = BN_Z(j1,2) REM qj1の解ベクトルzの中での位置
jj2 = BN_Z(j2,1) REM ψj2の解ベクトルzの中での位置
jjj2 = BN_Z(j2,2) REM qj2の解ベクトルzの中での位置
A(i, jj1) = A(i, jj1) - B1
A(i, jjj1) = A(i, jjj1) + H1
A(i, jj2) = A(i, jj2) - B2
A(i, jjj2) = A(i, jjj2) + H2
Next k
Next i
赤字の部分はいま追加したコメントで、後で考える必要のある部分です。
「A(i, jj1) = A(i, jj1) - B1」などの部分は、次の理由によります。一つの特異点iについて境界積分は具体的には、次の形になりました。
(ξi,ηi)を番号(節点番号)iの特異点だとして、
![]()
A(i, jj1) = A(i, jj1) - B1
A(i, jj2) = A(i, jj2) - B2
などとしとけば良いじゃん!、という話です。こうしとけば、「For k = 1 to B_Count」のLoopを回しただけで、自然に要素kとk+1に関する「重ね合わせ(足し算)」が起きるからです。そのためにこそ、要素-節点番号対応表EN_B(k,2)があるんですよ。
※ 宣言時にA(i, j)は、自動で全ての値が0に初期化されるのが普通です。
有限要素法などだと少なくとも2次元なので、要素-節点番号対応表がないとプログラムすら書けません。要素-節点番号対応表は、2次元領域を有限要素分割して初めて決まります。そういう訳でメッシュ切り(有限要素分割)と要素-節点番号対応表の生成は、FEMの中で最も手のかかる作業なんです、現実には(^^;)。
とりあえず境界方程式の核心部分は、これで生成できるはずです。次へ進みましょう。次には、
REM 領域要素番号kで領域積分を行うLoop
REM 要素番号kからEN_R(k,4)に従い節点を特定し、要素ごとに領域積分を実行
REM 上記結果に基づき、既知ベクトルwを作成
と書いてあります。念のため次の事を注意します。
これから最後のREM文に書いてある既知ベクトルwをセットする事になりますが、wの値は解ベクトル(未知ベクトル)zへセットします。これは連立方程式プログラムでは普通に行われる事で、係数マトリックスAと既知ベクトルとしてのzを連立方程式の解法部(たいていサブルーティン)へ送ると、zに解がセットされて返って来る仕掛けになるからです。こうすると既知ベクトル分のメモリを節約できます。
ここも基本は同じです。
REM 領域要素番号kで領域積分を行うLoop
For i = 1 to BN_Count
REM 特異点番号iの節点iを特定
h = 0
For k = 1 to R_Count
REM 要素番号kからEN_R(k,4)に従い節点を特定し、要素ごとに領域積分を実行
REM 特異点iと要素節点情報から積分値w0を計算
h = h + w0
Next k
REM 上記結果に基づき、既知ベクトルwを作成
z(i) = h
Next i
領域積分項wは、ラプラス方程式Δψ=gの既知関数g(x,y)に対応するものですが、今回g(x,y)は具体的に与えてないので、領域積分についてはこれ以上具体化しません。プログラムテストのところで、いくつか具体的例を出す予定です。
これで離散化された境界方程式はセットされました(されたはず(^^;))。残りは境界条件のセットです。
REM 境界節点番号jで境界条件位置を指定するLoop
REM 節点番号jからBN_BP(j,2)とBN_Z(j,2) に従い、(D1 D2)ブロックを作成
REM 節点番号jに従いBN_BV(j,2)の値をwブロックの後に並べ、(d1 d2)ブロックを作成
・・・なんですが、既に最外殻Loopは、全体係数マトリックスAの行番号iに関するものなのがわかっています。境界条件は境界方程式に対する補助条件なので、Aの中で境界方程式の行並びの後に、単純に並べれば良いだけです。境界方程式の行並びは特異点番号に一致し、それは特異点が境界節点のどれかと一致する事を表す並びでもあったので、境界方程式の行並びの行番号はi = 1~BN_Countでした。境界条件の行並びはi = BN_Count + 1から始まります。境界条件は1個の境界節点に必ず1個あります。従って、
REM 境界節点番号jで境界条件位置を指定するLoop
For i = BN_Count + 1 to 2 * BN_Count
REM 節点番号jからBN_BP(j,2)とBN_Z(j,2) に従い、(D1 D2)ブロックを作成
REM 節点番号jに従いBN_BV(j,2)の値をwブロックの後に並べ、(d1 d2)ブロックを作成
Next i
いまLoop内のREM文の中の節点番号jは、さっきの説明から、j=i-BN_Countです。そこに注意すると、
※「十進BASIC 最新版 概要」によると、IFブロックが使えます。
http://hp.vector.co.jp/authors/VA008683/basic02.htm
REM 境界節点番号jで境界条件位置を指定するLoop
For i = BN_Count + 1 to 2 * BN_Count
REM 行番号から節点番号を特定する
j = i - BN_Count
REM 節点番号jからBN_BP(j,2)とBN_Z(j,2) に従い、(D1 D2)ブロックを作成
REM 節点番号jに従いBN_BV(j,2)の値をwブロックの後に並べ、(d1 d2)ブロックを作成
If BN_BP(j,1) = 1 Then
REM ψjが既知が場合
jj = BN_Z(j,1) REM ψjの解ベクトルzの中での位置
A(i, jj) = 1 REM ψjの値を与えるので、Aの成分は1
z(i) = BN_BV(jj,1) REM ψjの値
ElseIf BN_BP(j,2) = 1 Then
REM qjが既知が場合
jj = BN_Z(j,2) REM qjの解ベクトルzの中での位置
A(i, jj) = 1 REM qjの値を与えるので、Aの成分は1
z(i) = BN_BV(jj,2) REM qjの値
End If
Next i
IFブロックを書く時もトップダウンの作法に従い、まずIf~ElseIf~End Ifのブロックの形を決めてから、必要なら説明のためのREM分をブロック内に書き込み、最後に具体的なコードを書く事をお奨めします。
最後に、全体係数マトリックスAと既知ベクトルとしてのzを連立方程式の解法部へ送ります。
REM 全体係数行列が出来たので、Gaussの掃き出し法にかけ、未知ベクトルzを求める
これも後で考えるべきものとして、赤字化しておきます。
[出力部]は短いので、それもここでやってしまいましょう。
REM BN_Z(j,2) に従いz(j)から値を読み出し、出力
For j = 1 to BN_Count
jj = BN_Z(j,1) REM zの中でのψjの位置
REM z(jj)をψjの出力ルーティンへ渡す
Next i
For j = 1 to BN_Count
jj = BN_Z(j,2) REM zの中でのqjの位置
REM z(jj)をqjの出力ルーティンへ渡す
Next i
赤字の部分は、サブルーティン化する予定です。でもその前に、本当にサブルーティン化する必要があるのか?を検討して、損はありません。
REM [メモ欄]
REM B_Count:境界要素数
REM EN_B(k,2):境界要素-節点対応表,k=1~B_Count
REM (k,1):要素kの始端の節点No.,(k,2):終端の節点No.
REM R_Count:領域要素数
REM EN_R(k,4):領域要素-節点対応表,k=1~R_Count
REM (k,j),j=1~4:jに従って要素kの要素節点No.を左回りに格納
REM BN_Count:境界節点数
REM BN(j,2):境界節点座標,j=1~BN_Count,(j,1):節点jのx座標,(j,2):y座標
REM RN_Count:領域節点数
REM RN(j,2):領域節点座標,j=1~RN_Count,(j,1):節点jのx座標,(j,2):y座標
REM BN_BP(j,2):節点の境界条件の有無,j=1~BN_Count
REM (j,1):節点jのψjが既知なら1、そうでないなら0
REM (j,2):節点jのqjが既知なら1、そうでないなら0
REM BN_BV(j,2):境界条件の値,j=1~BN_Count
REM (j,1):節点jのψjに与える値
REM (j,2):節点jのqjに与える値
REM z(i):未知ベクトル,i=1~2*BN_Count
REM BN_Z(j,2):節点-未知数対応表,j=1~BN_Count
REM (j,1):ψjのzの中の位置,(j,2):qjのzの中の位置
REM 節点j→ψj→z(j),節点j→qj→z(BN_Count+j)
REM A(i, j):全体係数マトリックス、i,j=1~2*BN_Count
REM [宣言部]
REM 配列寸法の上限は1000
REM B_Count:境界要素数
REM R_Count:領域要素数
Dim EN_B(1000,2) REM 境界要素-節点対応表,k=1~B_Count
Dim EN_R(1000,4) REM 領域要素-節点対応表,k=1~R_Count
REM BN_Count:境界節点数
REM RN_Count:領域節点数
Dim BN(1000,2) REM 境界節点座標,j=1~BN_Count
Dim RN(1000,2) REM 領域節点座標,j=1~RN_Count
Dim BN_BP(1000,2) REM 節点の境界条件の有無,j=1~BN_Count
Dim BN_BV(1000,2) REM 境界条件の値,j=1~BN_Count
Dim BN_Z(1000,2) REM 節点-未知数対応表,j=1~BN_Count
Dim z(1000) REM 未知ベクトル,i=1~2*BN_Count
Dim A(1000, 1000) REM 全体係数マトリックス、i,j=1~2*BN_Count
REM [入力部]
REM境界要素数B_Countと領域要素数R_Countは、事前に与えられると仮定する。
REM 境界要素と領域要素データは、要素ごとに節点番号が与えられると仮定する。
REM 与えられる節点番号は、左回りに順序付けられたものが与えられると仮定する。
REM 境界要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、境界要素-節点対応表EN_B(k,2)をセット
For k = 1 to B_Count
EN_B(k,1) = ?
EN_B(k,2) = ?
Next k
REM 領域要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、領域要素-節点対応表EN_R(k,4)をセット
For k = 1 to R_Count
For j = 1 to 4
EN_R(k,j) = ?
Next j
Next k
REM境界節点数BN_Countと領域節点数RN_Countは、事前に与えられると仮定する。
REM 境界節点を節点番号jで読み込むLoop
REM Loop内で境界節点座標を読み、BN(j,2)をセット
For j = 1 to BN_Count
BN(j,1) = ?
BN(j,2) = ?
Next j
REM 領域節点を節点番号jで読み込むLoop
REM Loop内で領域節点座標を読み、RN(j,2)をセット
For j = 1 to RN_Count
RN(j,1) = ?
RN(j,2) = ?
Next j
REM 境界条件の場所を節点番号jで読み込むLoop
REM Loop内で節点jの境界条件の有無を読み、BN_BP(j,2)をセット
For j = 1 to BN_Count
BN_BP(j,1) = ?
BN_BP(j,2) = ?
Next j
REM 境界条件の値を節点番号jで読み込むLoop
REM Loop内で節点jの境界条件の値を読み、BN_BV(j,2)をセット
For j = 1 to BN_Count
BN_BV(j,1) = ?
BN_BV(j,2) = ?
Next j
REM 節点番号jのLoopで、節点-未知数対応表BN_Z(j,2)をセット
REM (j,1):ψjのzの中の位置,(j,2):qjのzの中の位置
REM 対応は、節点j→ψj→z(j),節点j→qj→z(BN_Count+j)
For j = 1 to BN_Count
BN_Z(j,1) = j
BN_Z(j,2) = BN_Count + j
Next j
REM [計算部]
REM 境界要素番号kで境界積分を行うLoop
For i = 1 to BN_Count
REM 特異点番号iの節点iを特定
x0 = BN(i, 1) REM 節点iの(x,y)座標
y0 = BN(i, 2)
For k = 1 to B_Count
REM 要素番号kからEN_B(k,2)に従い節点を特定し、要素ごとに境界積分を実行
j1 = EN_B(k,1) REM 要素kの始端の節点番号
j2 = EN_B(k,2) REM 要素kの終端の節点番号
x1 = BN(j1, 1) REM 節点j1の(x,y)座標
y1 = BN(j1, 2)
x2 = BN(j2, 1) REM 節点j2の(x,y)座標
y2 = BN(j2, 2)
REM (x0,y0),(x1,y1),(x2,y2)から、要素kの境界積分値を計算
REM ψj1に関する結果をB1,qj1に関する結果をH1で表す
REM ψj2に関する結果をB2,qj2に関する結果をH2で表す
REM 上記結果に基づき、係数マトリックスBとHを作成
jj1 = BN_Z(j1,1) REM ψj1の解ベクトルzの中での位置
jjj1 = BN_Z(j1,2) REM qj1の解ベクトルzの中での位置
jj2 = BN_Z(j2,1) REM ψj2の解ベクトルzの中での位置
jjj2 = BN_Z(j2,2) REM qj2の解ベクトルzの中での位置
A(i, jj1) = A(i, jj1) - B1
A(i, jjj1) = A(i, jjj1) + H1
A(i, jj2) = A(i, jj2) - B2
A(i, jjj2) = A(i, jjj2) + H2
Next k
Next i
REM 領域要素番号kで領域積分を行うLoop
For i = 1 to BN_Count
REM 特異点番号iの節点iを特定
h = 0
For k = 1 to R_Count
REM 要素番号kからEN_R(k,4)に従い節点を特定し、要素ごとに領域積分を実行
REM 特異点iと要素節点情報から積分値w0を計算
h = h + w0
Next k
REM 上記結果に基づき、既知ベクトルwを作成
z(i) = h
Next i
REM 境界節点番号jで境界条件位置を指定するLoop
For i = BN_Count + 1 to 2 * BN_Count
REM 行番号から節点番号を特定する
j = i - BN_Count
REM 節点番号jからBN_BP(j,2)とBN_Z(j,2) に従い、(D1 D2)ブロックを作成
REM 節点番号jに従いBN_BV(j,2)の値をwブロックの後に並べ、(d1 d2)ブロックを作成
If BN_BP(j,1) = 1 Then
REM ψjが既知が場合
jj = BN_Z(j,1) REM ψjの解ベクトルzの中での位置
A(i, jj) = 1 REM ψjの値を与えるので、Aの成分は1
z(i) = BN_BV(jj,1) REM ψjの値
ElseIf BN_BP(j,2) = 1 Then
REM qjが既知が場合
jj = BN_Z(j,2) REM qjの解ベクトルzの中での位置
A(i, jj) = 1 REM qjの値を与えるので、Aの成分は1
z(i) = BN_BV(jj,2) REM qjの値
End If
Next i
REM 全体係数行列が出来たので、Gaussの掃き出し法にかけ、未知ベクトルzを求める
REM [出力部]
REM BN_Z(j,2) に従いz(j)から値を読み出し、出力
For j = 1 to BN_Count
jj = BN_Z(j,1) REM zの中でのψjの位置
REM z(jj)をψjの出力ルーティンへ渡す
Next i
For j = 1 to BN_Count
jj = BN_Z(j,2) REM zの中でのqjの位置
REM z(jj)をqjの出力ルーティンへ渡す
Next i
[境界要素法プログラムを設計する(入力部の実装)] [境界要素法]
[境界要素法プログラムを設計する(入力部の実装)]
1.なぜ入力部からなのか?
なぜ入力部から作るんでしょうか?。開発環境のコンパイラーにしてみれば、エラーが出ない限り、どっから手を付けられたってオッケーなはずです。だからこれは、人間の都合なんですよ。
一つは[入力部]→[計算部]→[出力部]の順に作って行くと、プログラムが完成した暁の実際の動作をプログラミング中にシミュレートする事になり、人間としては大変に考えやすい(^^)。
二つ目はテストのやりやすさです。[入力部]→[計算部]と作って行けば、[計算部]が上がった時点で一応のテストが可能になります。「開発サイクルは出来るだけ短く」です(^^)。それに一番間違えやすそうなのは、[計算部]に決まってます。[計算部]はできるだけ早くテストしたいし、ここがほとんどプログラムの核心です。そのテストの具合によっては[入力部]の仕様変更だってありえます。
以上は三層開発モデルの考え方に近いです。そこでは[入力部],[計算部],[出力部]は、[インターフェイス層],[ビジネスルール層],[データベース層]と難しそうに名を変えますが、結局やる事は同じなんですよ。
オブジェクトプログラミングの基本作法とか称して、三層開発モデルみたいな小難しいものに出会った事があるかも知れませんが、言ってる事はものすごく当たり前の事です。当たり前の事を誰も素直にやろうとしないから、そういう開発モデルが提唱されただけなんです。それはISOも同じです(^^;)。
余談ですが業務アプリの開発では、[入力部],[計算部],[出力部]を同時並行に開発する事もあります。エッ?できるの?って気もしますが(^^;)、例えば[計算部]にとって[入力部]は一種の外部環境です。そこでモックと呼ばれる仮想オブジェクトを作り、[入力部]の仕様をモックでシミュレートして[入力部]が作ったかのような外部データを[計算部]に渡しテストする訳です。ただこれは、相当な金と時間とマンパワー(と優秀な人材)がないと、ほとんど実現不可能です。ここではやらないのが無難ですな(^^;)。
ちなみにプログラムを書くことを実装と言います。実装で行われる作業全体の事を製造と言ったりします。
2.入力部の実装
前回の[メモ欄]と[宣言部]を参照しつつ、[入力部]の冒頭に書いてある事を読みます。その冒頭には、
REM境界要素数B_Countと領域要素数R_Countは、事前に与えられると仮定する。
REM 境界要素と領域要素データは、要素ごとに節点番号が与えられると仮定する。
REM 与えられる節点番号は、左回りに順序付けられたものが与えられると仮定する。
とあり、その直後には、
REM 境界要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、境界要素-節点対応表EN_B(k,2)をセット
とあります。
いま本当に具体的な入力ルーティンは書けないのですが、最初の仮定通りのものが既にあるのなら、EN_B(k,2)のセットは、以下です。ただし代入文のLETは省略してます(面倒なので)。後で補充して下さい(^^;)。
For k = 1 to B_Count
EN_B(k,1) = ?
EN_B(k,2) = ?
Next k
となります。ここで「?」は、最初の仮定により与えられる値です。でも図-1を見れば、EN_B(k,1) = k,EN_B(k,2) = k+1,k = B_Countの時はEN_B(k,2) = 1、ってのがわかります。こういう風に与えてもOKなんですが個人的には、事前にちゃんと「?」のデータを作る事をお奨めします。
次の、
REM 領域要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、領域要素-節点対応表EN_R(k,4)をセット
も同様です。これは図-2のように、領域要素が4角形要素を想定したケースです。
For k = 1 to R_Count
For j = 1 to 4
EN_R(k,j) = ?
Next j
Next k
後も同様なので、直接[入力部]にコードを書き込んで、今回は終了します。
REM [メモ欄]
REM B_Count:境界要素数
REM EN_B(k,2):境界要素-節点対応表,k=1~B_Count
REM (k,1):要素kの始端の節点No.,(k,2):終端の節点No.
REM R_Count:領域要素数,Region Elements Countの略
REM EN_R(k,4):領域要素-節点対応表,k=1~R_Count
REM (k,j),j=1~4:jに従って要素kの要素節点No.を左回りに格納
REM BN_Count:境界節点数
REM BN(j,2):境界節点座標,j=1~BN_Count,(j,1):節点jのx座標,(j,2):y座標
REM RN_Count:領域節点数
REM RN(j,2):領域節点座標,j=1~RN_Count,(j,1):節点jのx座標,(j,2):y座標
REM BN_BP(j,2):節点の境界条件の有無,j=1~BN_Count
REM (j,1):節点jのψjが既知なら1、そうでないなら0
REM (j,2):節点jのqjが既知なら1、そうでないなら0
REM BN_BV(j,2):境界条件の値,j=1~BN_Count
REM (j,1):節点jのψjに与える値
REM (j,2):節点jのqjに与える値
REM z(i):未知ベクトル,i=1~2*BN_Count
REM BN_Z(j,2):節点-未知数対応表,j=1~BN_Count
REM (j,1):ψjのzの中の位置,(j,2):qjのzの中の位置
REM 節点j→ψj→z(j),節点j→qj→z(BN_Count+j)
REM [宣言部]
REM 配列寸法の上限は1000
REM B_Count:境界要素数
REM R_Count:領域要素数
Dim EN_B(1000,2) REM 境界要素-節点対応表,k=1~B_Count
Dim EN_R(1000,4) REM 領域要素-節点対応表,k=1~R_Count
REM BN_Count:境界節点数
REM RN_Count:領域節点数
Dim BN(1000,2) REM 境界節点座標,j=1~BN_Count
Dim RN(1000,2) REM 領域節点座標,j=1~RN_Count
Dim BN_BP(1000,2) REM 節点の境界条件の有無,j=1~BN_Count
Dim BN_BV(1000,2) REM 境界条件の値,j=1~BN_Count
Dim BN_Z(1000,2) REM 節点-未知数対応表,j=1~BN_Count
Dim z(1000) REM 未知ベクトル,i=1~2*BN_Count
REM [入力部]
REM境界要素数B_Countと領域要素数R_Countは、事前に与えられると仮定する。
REM 境界要素と領域要素データは、要素ごとに節点番号が与えられると仮定する。
REM 与えられる節点番号は、左回りに順序付けられたものが与えられると仮定する。
REM 境界要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、境界要素-節点対応表EN_B(k,2)をセット
For k = 1 to B_Count
EN_B(k,1) = ?
EN_B(k,2) = ?
Next k
REM 領域要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、領域要素-節点対応表EN_R(k,4)をセット
For k = 1 to R_Count
For j = 1 to 4
EN_R(k,j) = ?
Next j
Next k
REM境界節点数BN_Countと領域節点数RN_Countは、事前に与えられると仮定する。
REM 境界節点を節点番号jで読み込むLoop
REM Loop内で境界節点座標を読み、BN(j,2)をセット
For j = 1 to BN_Count
BN(j,1) = ?
BN(j,2) = ?
Next j
REM 領域節点を節点番号jで読み込むLoop
REM Loop内で領域節点座標を読み、RN(j,2)をセット
For j = 1 to RN_Count
RN(j,1) = ?
RN(j,2) = ?
Next j
REM 境界条件の場所を節点番号jで読み込むLoop
REM Loop内で節点jの境界条件の有無を読み、BN_BP(j,2)をセット
For j = 1 to BN_Count
BN_BP(j,1) = ?
BN_BP(j,2) = ?
Next j
REM 境界条件の値を節点番号jで読み込むLoop
REM Loop内で節点jの境界条件の値を読み、BN_BV(j,2)をセット
For j = 1 to BN_Count
BN_BV(j,1) = ?
BN_BV(j,2) = ?
Next j
REM 節点番号jのLoopで、節点-未知数対応表BN_Z(j,2)をセット
REM (j,1):ψjのzの中の位置,(j,2):qjのzの中の位置
REM 対応は、節点j→ψj→z(j),節点j→qj→z(BN_Count+j)
For j = 1 to BN_Count
BN_Z(j,1) = j
BN_Z(j,2) = BN_Count + j
Next j
REM [計算部]
REM 境界要素番号kで境界積分を行うLoop
REM 要素番号kからEN_B(k,2)に従い節点を特定し、要素ごとに境界積分を実行
REM 上記結果に基づき、係数マトリックスBとHを作成
REM 領域要素番号kで領域積分を行うLoop
REM 要素番号kからEN_R(k,4)に従い節点を特定し、要素ごとに領域積分を実行
REM 上記結果に基づき、既知ベクトルwを作成
REM 境界節点番号jで境界条件位置を指定するLoop
REM 節点番号jからBN_BP(j,2)とBN_Z(j,2) に従い、(D1 D2)ブロックを作成
REM 節点番号jに従いBN_BV(j,2)の値をwブロックの後に並べ、(d1 d2)ブロックを作成
REM 全体係数行列が出来たので、Gaussの掃き出し法にかけ、未知ベクトルzを求める
REM [出力部]
REM BN_Z(j,2) に従いz(j)から値を読み出し、出力
(執筆 ddt³さん)
[境界要素法プログラムを設計する(アウトライン)] [境界要素法]
[境界要素法プログラムを設計する(アウトライン)]
1.開発範囲の決定
これは業務アプリの開発で言えば、顧客がどこまでの成果品を望むか?です。顧客の要求は常にドンダケ~なんですが、開発側としては出来るだけ簡単なものにしたい訳です(仕事したくないから(^^;))。今回の顧客は我々です。つまり開発者です。なので今回は、開発側の事情最優先です(^^)。
境界要素法プログラムの目的は、離散化された境界方程式、
![]()
を作る事にほぼ尽きます。しかし(1)はそのままでは解けないのでした。以下の条件を考慮する必要がありました。
[1]境界条件
これは、未知ベクトルψ,qの一部に値を与える補助方程式として実装するのが簡単でした。
[2]角点の処理
これは角点を表す節点jのqjが、qj(1),qj(2)と2つになり、qの成分数が増える事を意味します。それに伴い補助条件の追加も必要でした。しかも追加の仕方は、境界条件の与えられ方により変化しました。
最初から[2]を扱うと面倒そうです。例えば(1)+[1]だけなら、組み立てる連立方程式の形は、

になります。(D1 D2)ブロックは、境界条件で値を与えられる節点番号の列成分が1で、他は全て0の行列です。(d1 d2)tブロックは与える値のベクトルです。
ψとqの成分は、節点jのψjとqjを表しますが、z=(ψ q)tと一つの未知ベクトルとしてまとめると、qjのjとz上での成分番号が、既にこの時点でずれます。幸いψとqの成分数は同じなので、それをnとして、
節点j→ψj→z(j),節点j→qj→z(n+j) (3)
ではあります。z(j)などは、配列zのj成分の意味で使ってます。
これに[2]が加わると、qの成分数が角点が現れるたびに増え、(3)程度の対応ではすまなくなります。当然HとD2の列数も増え、どう増えるかなどを制御しなければなりません。さらにここに新たに補助方程式が加わりますが、加え方は一定ではないのでした。
やっぱり最初は(1)+[1]ですよね?。(1)+[1]のプログラムをテストして動作確認し、自信を持って複雑そうな[2]に進むのが妥当です。(1)+[1]の基本が出来れば、[2]への対処のポイントも絞れるはずです。要するに適切な実践に勝る教師なし!です。
もう一つ考慮すべきは、テストの容易さです。作ったプログラムは必ずテストしなければなりません。例えば全部作ってから動かなかったら、バグの特定にも難儀します。その時に「(1)+[1]まではOKよ」という事実があると、格段に楽になります。
業務アプリの開発でも、開発サイクルを出来るだけ短く区切って頻繁にテストし、より複雑な段階へ進む事が推奨されアジャイル開発と言います。その際、個々の開発サイクルでの成果は一つの製品であり、次の段階はその拡張仕様という見方をします。
2.大枠決め
「実践に勝る教師なし!」なんて言うものだから、すぐにプログラムをボトムアップで作成しようします。気持ちはわかります。ボトムアップ方式なら具体的な数式なんかを、どんどん書いて行けるので。でも「適切な」実践ですからね。開発の基本は常にトップダウンです。
プログラムの目的から始まって、何をやりたいか?何をやるべきか?のアウトラインをトップダウンで決めます。それを詳細化して行くと、局所的なボトムアップ作業へと自然につながります。こうすると常に全体を見渡しながら局所的な具体化作業に集中できます。こうすると「後で考えれば明らかだったよなぁ~」みたいな不用意で不必要なバグは激減します。
もう一つ大事なのは、トップダウン中の方針決定には、必ず明確な理由がある事。プログラム作成は、何をやろうと一長一短。すると局所的な便利さ不便さから、大域的な方針まで変更したくなります。その時、変更するのか我慢すべきか判断が必要です。全体系の整合性を保つ判断根拠になるのが、明確な決定理由です。
 自分は一時期アプリ開発で飯を食ってたので、プロの言葉は信じて良いですよぉ~(←ほんとか?(^^;))。
自分は一時期アプリ開発で飯を食ってたので、プロの言葉は信じて良いですよぉ~(←ほんとか?(^^;))。
まず実用的なプログラムの全体構成は一個しかありません。図-3です。これ以外ないですよね?。ここで問題になるのは[メモ欄]だと思いますが、これは必須です。ここにプログラムの仕様を書いて行きます。[メモ欄]を読めば、全体を見渡せるように書きます。これを怠ると、たいてい後でこっぴどい目に合います。
トップダウン思考でキーになるのが、「実行者をさがせ!」です。特定された実行者が、プログラムを動かすと考えて下さい。このプログラムの目的である式(2)を見てみます。
(D1 D2)と(d1 d2)tの部分は、どうやら値を並べるだけなのでどうとでもなりそうです。対して(B H)と(w)tの部分は、今までやってきた積分式を使うべきところです。
BやHは境界積分の項です。境界積分は個々の境界要素の境界節点を特定し、主に節点情報に基づいて積分値を得た後、それを全ての要素について足すのでした。その足し算を、行列という省略記法で書いたものがB,Hです。
wは領域積分項です。同様に、領域要素の節点を特定し節点情報に基づいて積分値を得た後、それを全ての要素について足します。
自分は、このプログラムの実行者は「要素」だと思います。
境界要素や領域要素は具体的には節点で定義されます。しかし図-1,2に示すように、同じ節点が隣の要素(一つとは限らない)に共有されたりします。従って要素-節点対応表が必要です。こんな具合です。
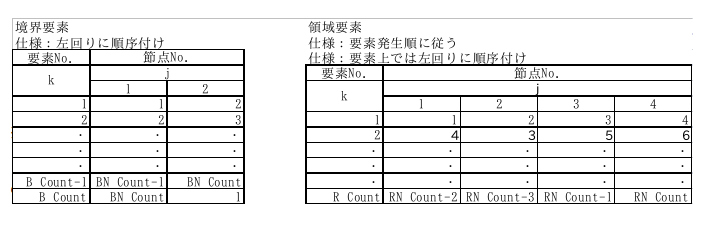
※ 領域要素の番号付けは、具体的な要素発生が不明なので例です。
ここでB_Countは境界要素数,BN_Countは境界節点数。R_Countは領域要素数,RN_Countは領域節点数。これらは[入力部]で具体的に要素データと節点データが与えられた時に、セットされるべきものです。表中のjの下の1,2と1,2,3,4は、境界要素では1:始端,2終端を表し、領域要素ではこの順番で左回りに節点を順序付ける事を意味します。
要素-節点対応表はもちろん配列で定義しますが、十進BASICでは可変長配列が使えないので、最初に配列寸法の上限を決めておく必要があります。ここでは、配列寸法上限:1000、としておきます。
境界要素に対する要素-節点対応表は、EN_B(k,2)の形にします。
kが境界要素番号,2の並びが先の1,2に対応します。EN_B(k,2)の内容は、(k,1),(k,2)で指定される境界要素kが持つ節点番号です。
同様に領域要素ではEN_R(k,4)の形にします。
kが領域要素番号,4の並びが先の1~4に対応し、(k,j),j=1~4で指定される領域要素kが持つ節点番号を格納します。
節点の具体的情報が必要です。節点データは当然、座標データで入力されます。これも配列で定義すべきです。境界節点座標はBN(j,2),領域節点座標はRN(j,2)とします。jが節点番号,2の並びがx座標,y座標です。
次に未知ベクトルψとqです。式(2)の計算方針では、ψとqを一つの未知ベクトルz=(ψ q)tとして扱います。それが連立方程式の組み方として、最も単純だったからです。
理想的には節点jにおいてψj,qjですが、(ψ q)tとまとめた時点でもうその扱いはできません。ψの成分数は明らかに境界節点数BN_Countと同じです。j→ψj→z(j)です。従ってj→qj→z(BN_Count+j)です。確かにこの規則があれば、各未知数のzの中での位置の特定は簡単です。しかしいずれ[2]を考慮するのでした。その時には、もっと複雑な対応付けに迫られます。節点-未知数対応表も用意しておきましょう。後で手を加えたとしても、基本の形だけは、ここで整えます。
節点-未知数対応表はBN_Z(j,2)とします。
jが節点番号で,(j,1)がψjに対応するz上の成分番号,(j,2)はqjに対応するz上の成分番号です。
式(1)の(D1 D2)と(d1 d2)tブロックは、境界条件が与えられる場所と、その値を示すものでした。これらの情報も[入力部]でセットされるべきものです。境界条件が与えられる場所の情報は、BN_BP(j,2)とします。
jは節点番号で、(j,1)にはψjが与えられる/与えられないで1または0をセットします。(j,2)にはqjが与えられる/与えられないで1または0をセットします。(D1 D2)ブロックで境界条件を与えるべき列番号は、節点番号jからBN_Z(j,1または2)の値でわかります。(D1 D2)の成分に与える値は1です。
境界条件の値の情報は、BN_BV(j,2)とします。BN_BP(j,2)と同様です。BN_BP(j,2)の指定に対応する形で、具体的な境界条件の値を格納します。(d1 d2)tブロックで境界条件の境界値を与えるべき行番号は、jに従って、zの中で(ψ q)tの後に順番に並べるだけです。
とりあえず最外殻のアウトライン決定作業としては、こんなものです。しかしここまででも、かなり沢山の事を決定し、わかった事もあります。だから[メモ欄]に決めた事を書いておくんですよ。平たく言えば、変数定義の説明です。また宣言部では必要とわかった変数(配列)を、この時点でちゃんと宣言します。後で勝手に変なものを作らせないためにです。[入力部]~[出力部]にも、わかった事を出来るだけ具体的に書いておきます。特に実行者が「要素」である事を明確にします。
※後で勝手に変なものを作るのは、じつは本人だったりするんですよね(^^;)。
3.プログラミング言語の選択
本当は、1.と2.を勘案しながら、システムを記述する言語を選択すべきなんですが、途中でちょろっと漏らしたように、まぁ~十進BASICで行けると思います。アマチュアにとって「無料」は大事です(^^)。
REM [メモ欄]
REM B_Count:境界要素数
REM EN_B(k,2):境界要素-節点対応表,k=1~B_Count
REM (k,1):要素kの始端の節点No.,(k,2):終端の節点No.
REM R_Count:領域要素数,Region Elements Countの略
REM EN_R(k,4):領域要素-節点対応表,k=1~R_Count
REM (k,j),j=1~4:jに従って要素kの要素節点No.を左回りに格納
REM BN_Count:境界節点数
REM BN(j,2):境界節点座標,j=1~BN_Count,(j,1):節点jのx座標,(j,2):y座標
REM RN_Count:領域節点数
REM RN(j,2):領域節点座標,j=1~RN_Count,(j,1):節点jのx座標,(j,2):y座標
REM BN_BP(j,2):節点の境界条件の有無,j=1~BN_Count
REM (j,1):節点jのψjが既知なら1、そうでないなら0
REM (j,2):節点jのqjが既知なら1、そうでないなら0
REM BN_BV(j,2):境界条件の値,j=1~BN_Count
REM (j,1):節点jのψjに与える値
REM (j,2):節点jのqjに与える値
REM z(i):未知ベクトル,i=1~2*BN_Count
REM BN_Z(j,2):節点-未知数対応表,j=1~BN_Count
REM (j,1):ψjのzの中の位置,(j,2):qjのzの中の位置
REM 節点j→ψj→z(j),節点j→qj→z(BN_Count+j)
REM [宣言部]
REM 配列寸法の上限は1000
REM B_Count:境界要素数
REM R_Count:領域要素数
Dim EN_B(1000,2) REM 境界要素-節点対応表,k=1~B_Count
Dim EN_R(1000,4) REM 領域要素-節点対応表,k=1~R_Count
REM BN_Count:境界節点数
REM RN_Count:領域節点数
Dim BN(1000,2) REM 境界節点座標,j=1~BN_Count
Dim RN(1000,2) REM 領域節点座標,j=1~RN_Count
Dim BN_BP(1000,2) REM 節点の境界条件の有無,j=1~BN_Count
Dim BN_BV(1000,2) REM 境界条件の値,j=1~BN_Count
Dim BN_Z(1000,2) REM 節点-未知数対応表,j=1~BN_Count
Dim z(1000) REM 未知ベクトル,i=1~2*BN_Count
REM [入力部]
REM境界要素数B_Countと領域要素数R_Countは、事前に与えられると仮定する。
REM 境界要素と領域要素データは、要素ごとに節点番号が与えられると仮定する。
REM 与えられる節点番号は、左回りに順序付けられたものが与えられると仮定する。
REM 境界要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、境界要素-節点対応表EN_B(k,2)をセット
REM 領域要素を要素番号kで読み込むLoop
REM Loop内で要素ごとの節点番号を読み、領域要素-節点対応表EN_R(k,4)をセット
REM境界節点数BN_Countと領域節点数RN_Countは、事前に与えられると仮定する。
REM 境界節点を節点番号jで読み込むLoop
REM Loop内で境界節点座標を読み、BN(j,2)をセット
REM 領域節点を節点番号jで読み込むLoop
REM Loop内で領域節点座標を読み、RN(j,2)をセット
REM 境界条件の場所を節点番号jで読み込むLoop
REM Loop内で節点jの境界条件の有無を読み、BN_BP(j,2)をセット
REM 境界条件の値を節点番号jで読み込むLoop
REM Loop内で節点jの境界条件の値を読み、BN_BV(j,2)をセット
REM 節点番号jのLoopで、節点-未知数対応表BN_Z(j,2)をセット
REM (j,1):ψjのzの中の位置,(j,2):qjのzの中の位置
REM 対応は、節点j→ψj→z(j),節点j→qj→z(BN_Count+j)
REM [計算部]
REM 境界要素番号kで境界積分を行うLoop
REM 要素番号kからEN_B(k,2)に従い節点を特定し、要素ごとに境界積分を実行
REM 上記結果に基づき、係数マトリックスBとHを作成
REM 領域要素番号kで領域積分を行うLoop
REM 要素番号kからEN_R(k,4)に従い節点を特定し、要素ごとに領域積分を実行
REM 上記結果に基づき、既知ベクトルwを作成
REM 境界節点番号jで境界条件位置を指定するLoop
REM 節点番号jからBN_BP(j,2)とBN_Z(j,2) に従い、(D1 D2)ブロックを作成
REM 節点番号jに従いBN_BV(j,2)の値をwブロックの後に並べ、(d1 d2)ブロックを作成
REM 全体係数行列が出来たので、Gaussの掃き出し法にかけ、未知ベクトルzを求める
REM [出力部]
REM BN_Z(j,2) に従いz(j)から値を読み出し、出力
(執筆 ddt³さん)
[領域積分項の扱い(ラプラス型)] [境界要素法]
[領域積分項の扱い(ラプラス型)]
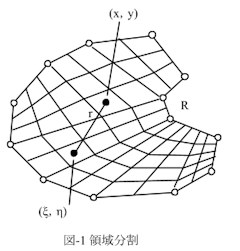
・・・後は領域積分項です。次式の右辺です。

領域積分はたいてい数値積分します。厳密にやろうとすると境界積分より大変なのと、式(1),(2)右辺の積算値さえ出せれば良いので、多少のいい加減さは許容されるからです。なので数値積分のための領域分割メッシュも有限要素法のときほど綺麗でなくてOKです。図-1のように領域メッシュの角に、必ずしも境界節点がなくたってOKです。たいていは3角形か4角形メッシュになると思います。
![]()
でした。rが十分大きいとlog(r)の挙動はおとなしくなるので、特異点(ξ,η)を持たない分割要素での積分は、ガウスの3点公式か4点公式を使えば十分と思われます。個人的には分割を十分細かくして、要素重心(xc,yc)の値でψ*とgを代表し、
![]()
で十分ではないかな?と思っています。式(4)でk=1~mは分割要素の番号,Akは要素kの面積。Σに特異点(ξ,η)を持つ要素は含めません。それはS0として別途扱います。
ここでも問題になるのは、特異点(ξ,η)を持つ要素です。rが0に近づくとlog(r)の絶対値は急速に増加するので、gはg(ξ,η)で代表させるのが良かろうと思われます。
![]()
とやりたい訳です。∫s dxdyは、特異点を持つ要素Sでの積分を表します。
ガウスの発散定理を前提にします。不定積分、

は境界積分で扱ってきたものと同じタイプです。ガウスの発散定理から、
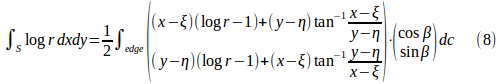
となります。∫edge dcは、要素Sの辺上での線積分を表します。βは要素辺の外法線方向,・は内積です。
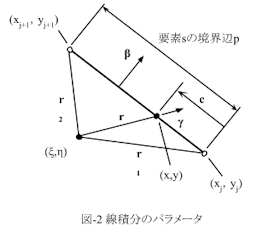
式(8)のx,yを図-2に示した積分パラメータcで表し、その線積分を厳密に行う事は(たぶん)可能ですが、非常に大変そうです。それにもう十分いい加減な近似をやってるんだし「合計さえわかれば良い」という態度をつらぬきます(^^;)。図-2に示した一つの要素辺の端点で式(8)の被積分関数の値を計算し、辺上で線形近似する事で数値積分する事にします。(8)の最初の被積分関数のx成分とy成分をΨ(x)(c),Ψ(y)(c)として、
![]()
とおくと図-2より、

になります。γ1とγ2はr1とr2の方向です。同様に、
![]()
これらを用いるとΨ(x)(c),Ψ(y)(c)は線形近似だったので、辺pの長さをLpとして辺p上で、
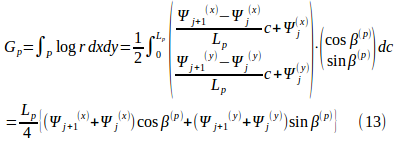
です。従って式(5)は、
![]()
と評価できます。
(ξ,η)が(xj,yj)や(xj+1,yj+1)に近づいた極限では、(9)~(12)の形から明らかなように、r1→0またはr2→0の極限で値0に収束し、境界方程式(1)にも対応可能です(^^)。ただしここでも計算プラグラム上の使い分けは必要になります。
以上で必要な計算式は全て出揃いました。計算プラグラムの作成に突入できます!(^^)。でもその詳細は、ちょっと待って下さいね(^^;)。



